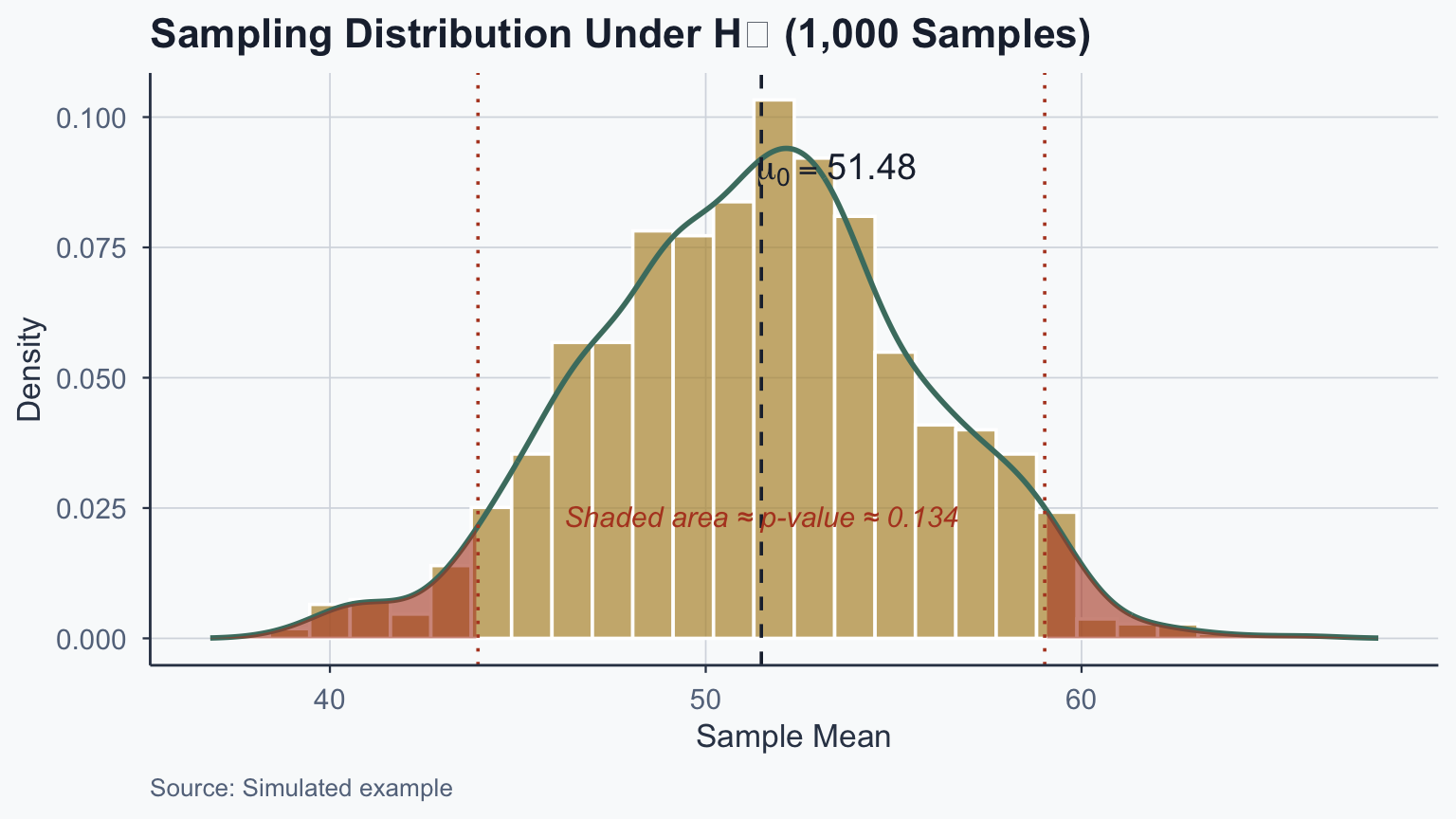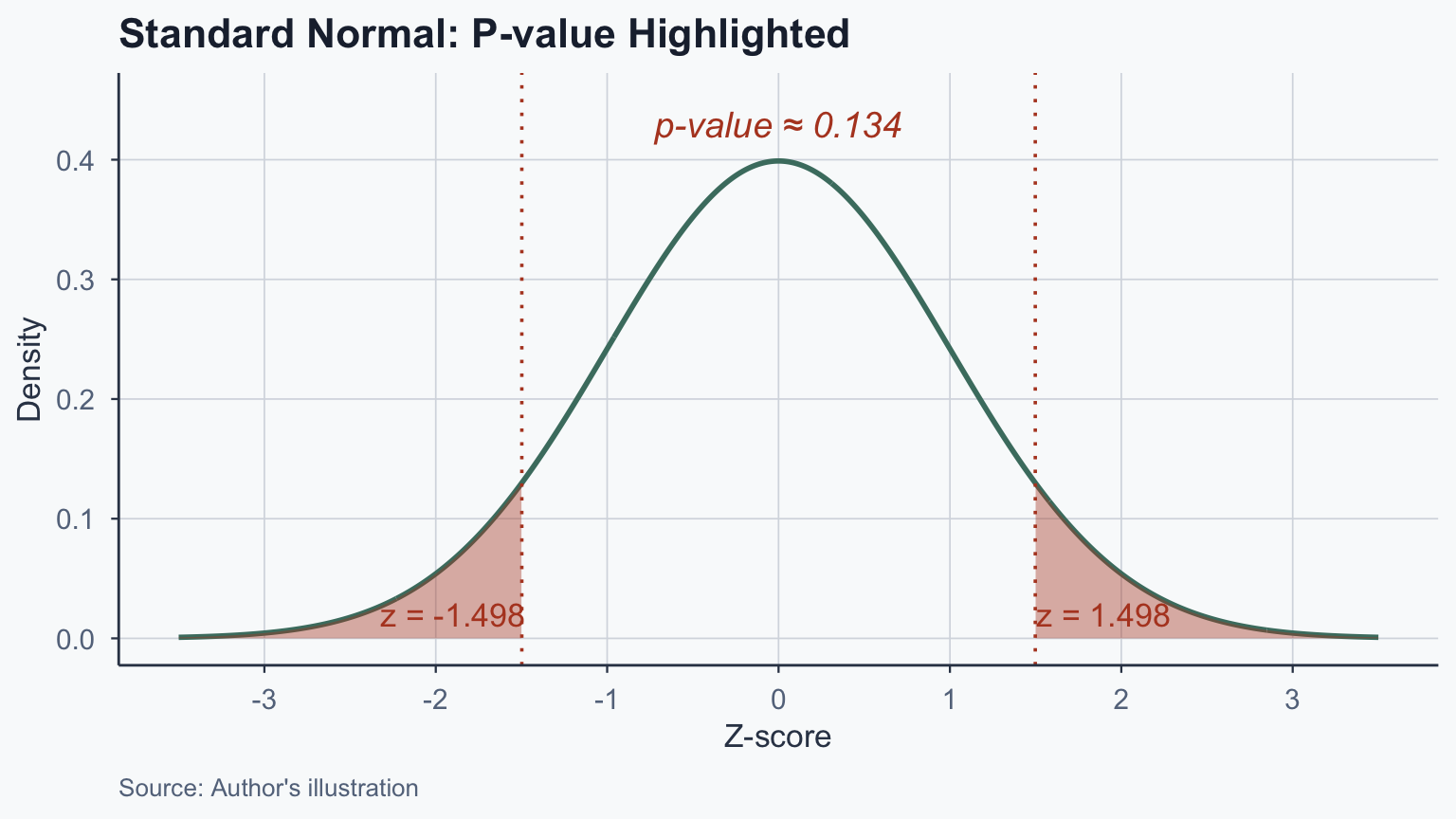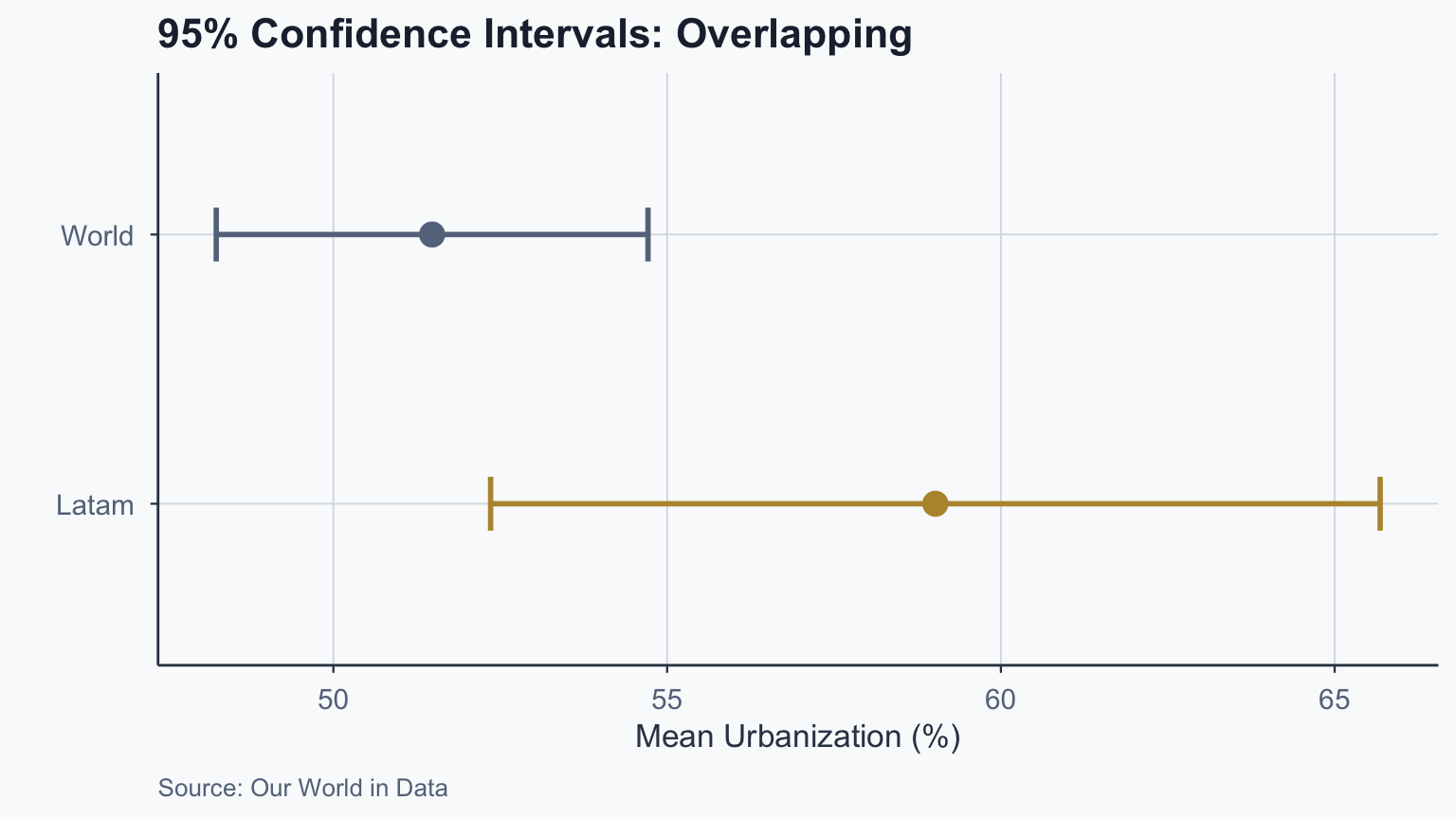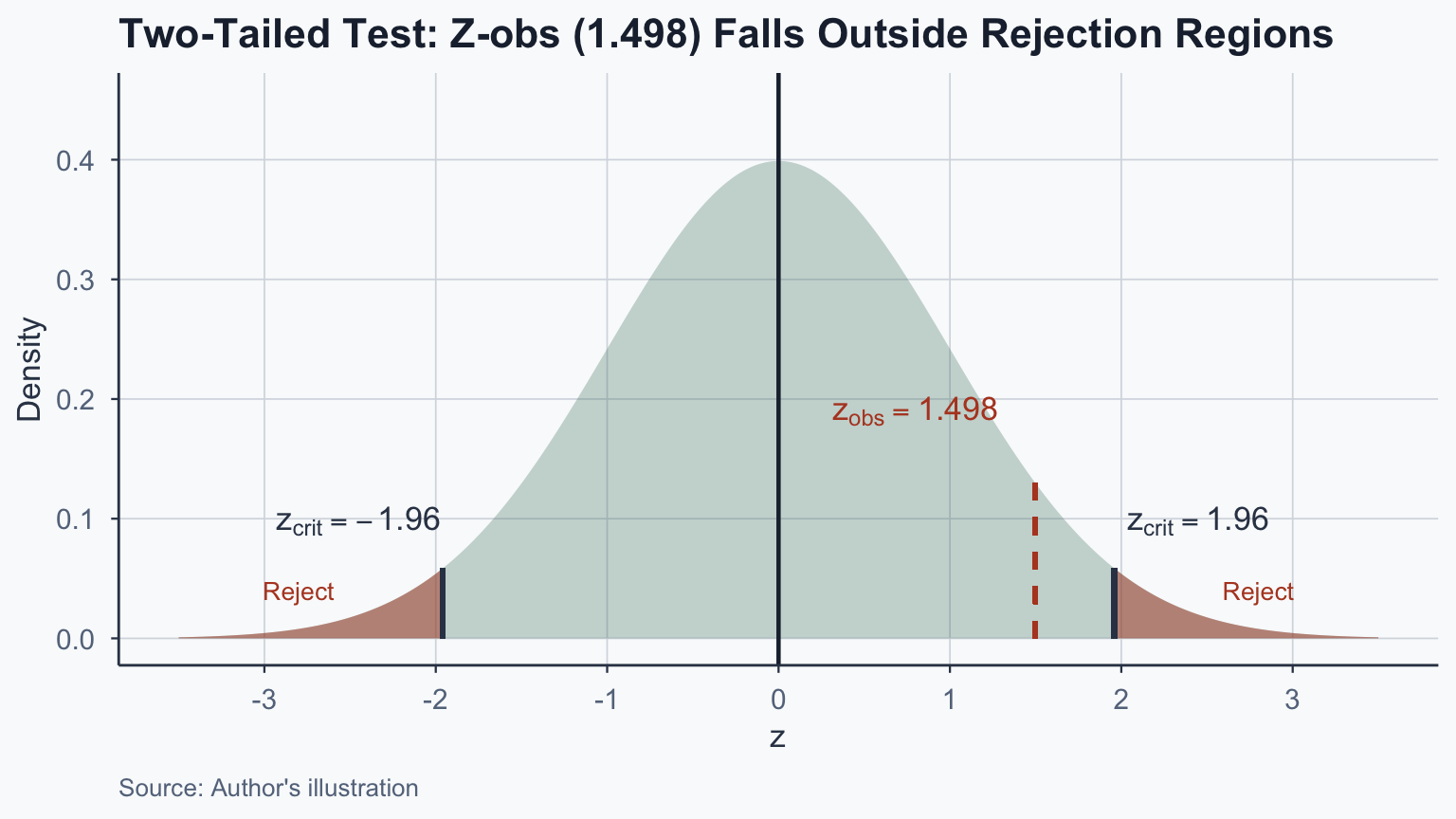
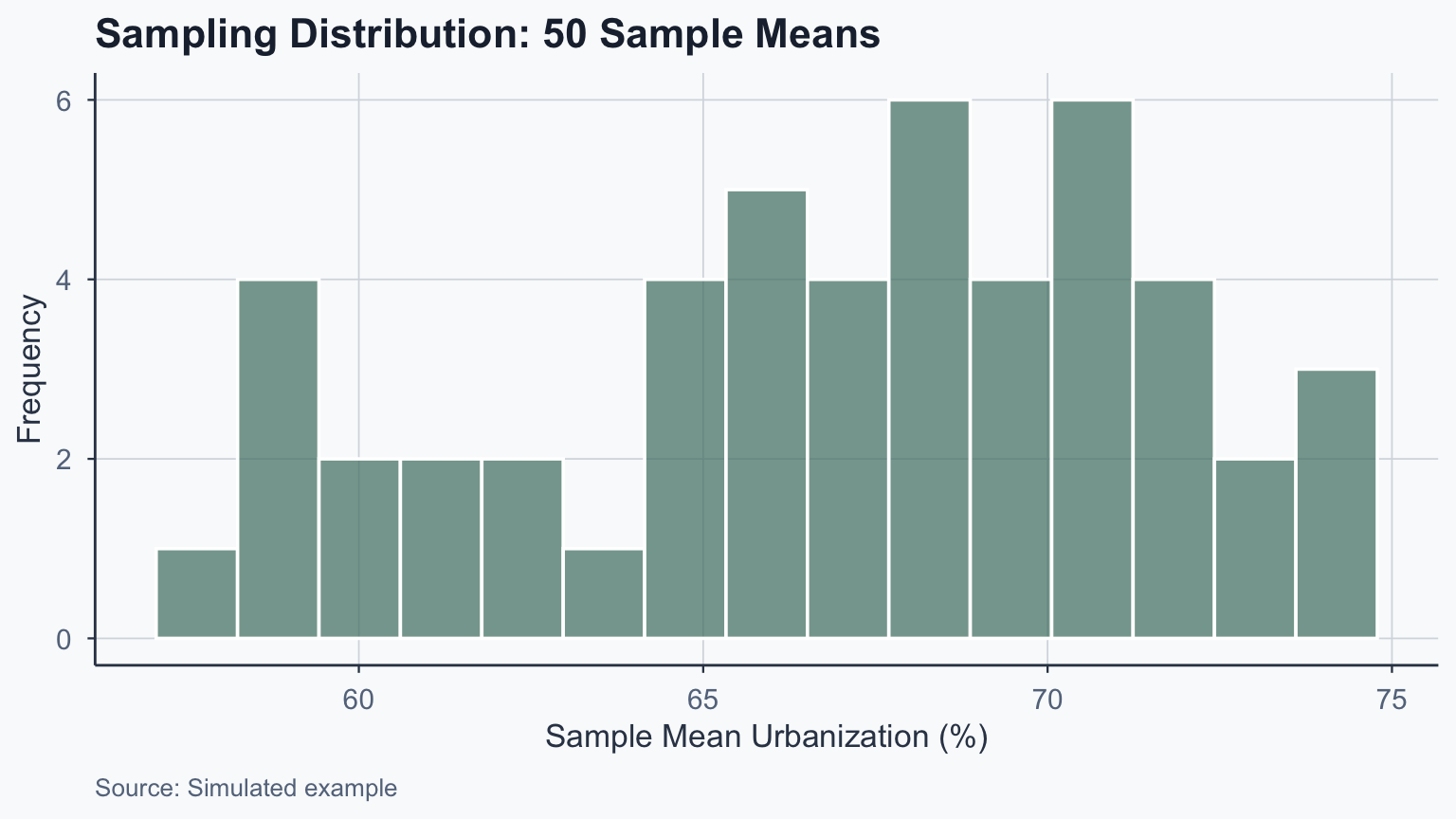
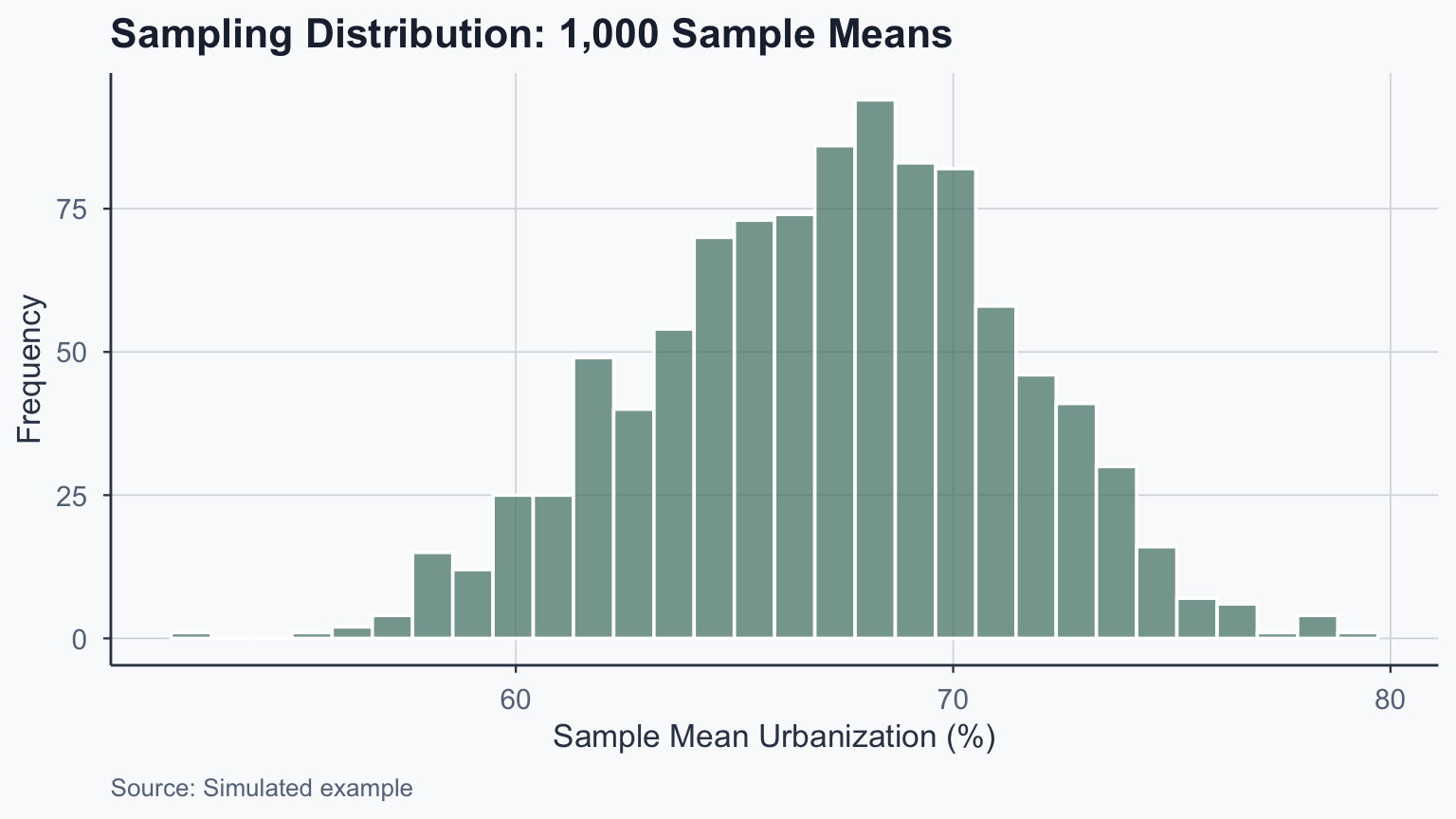
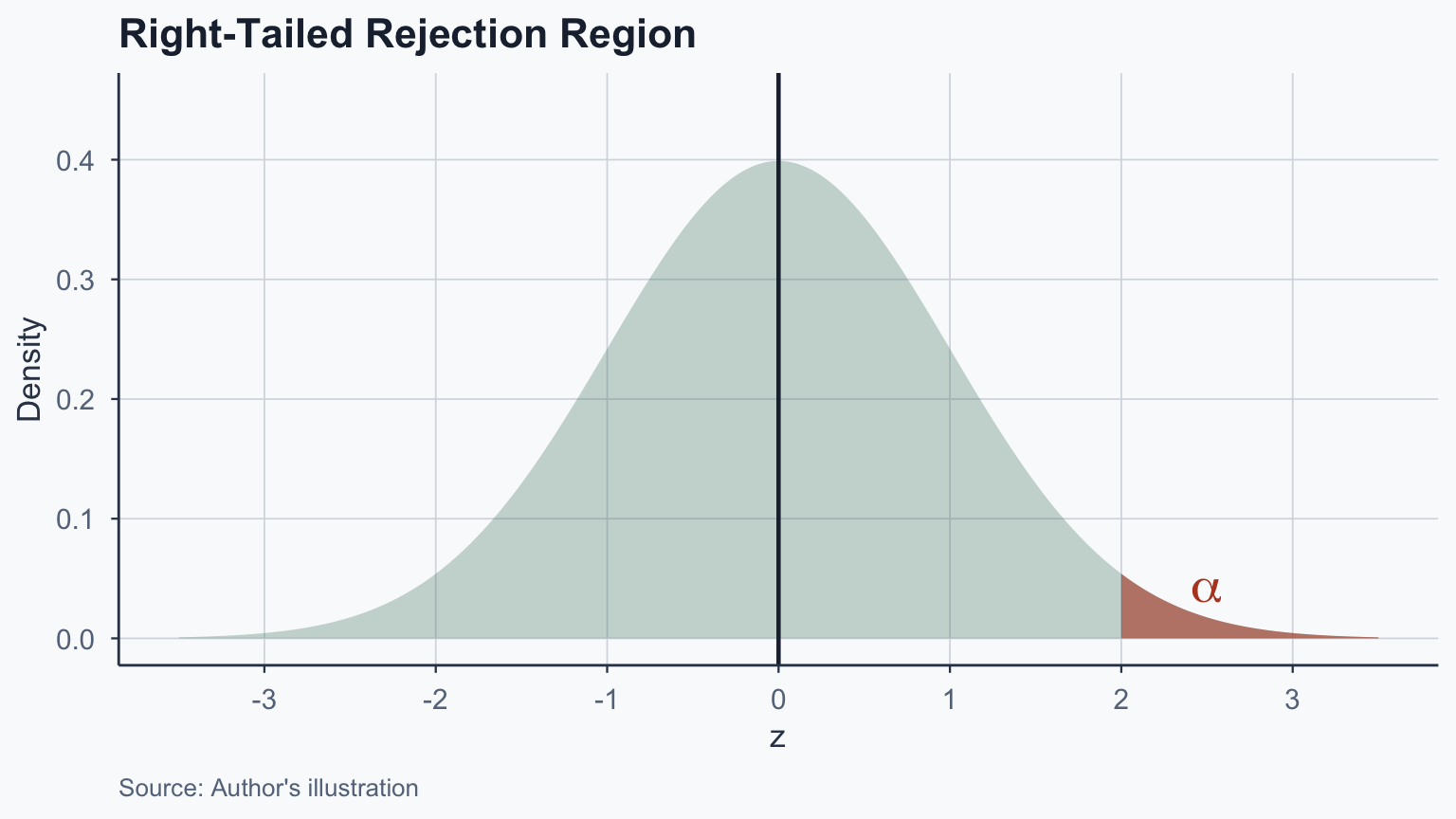
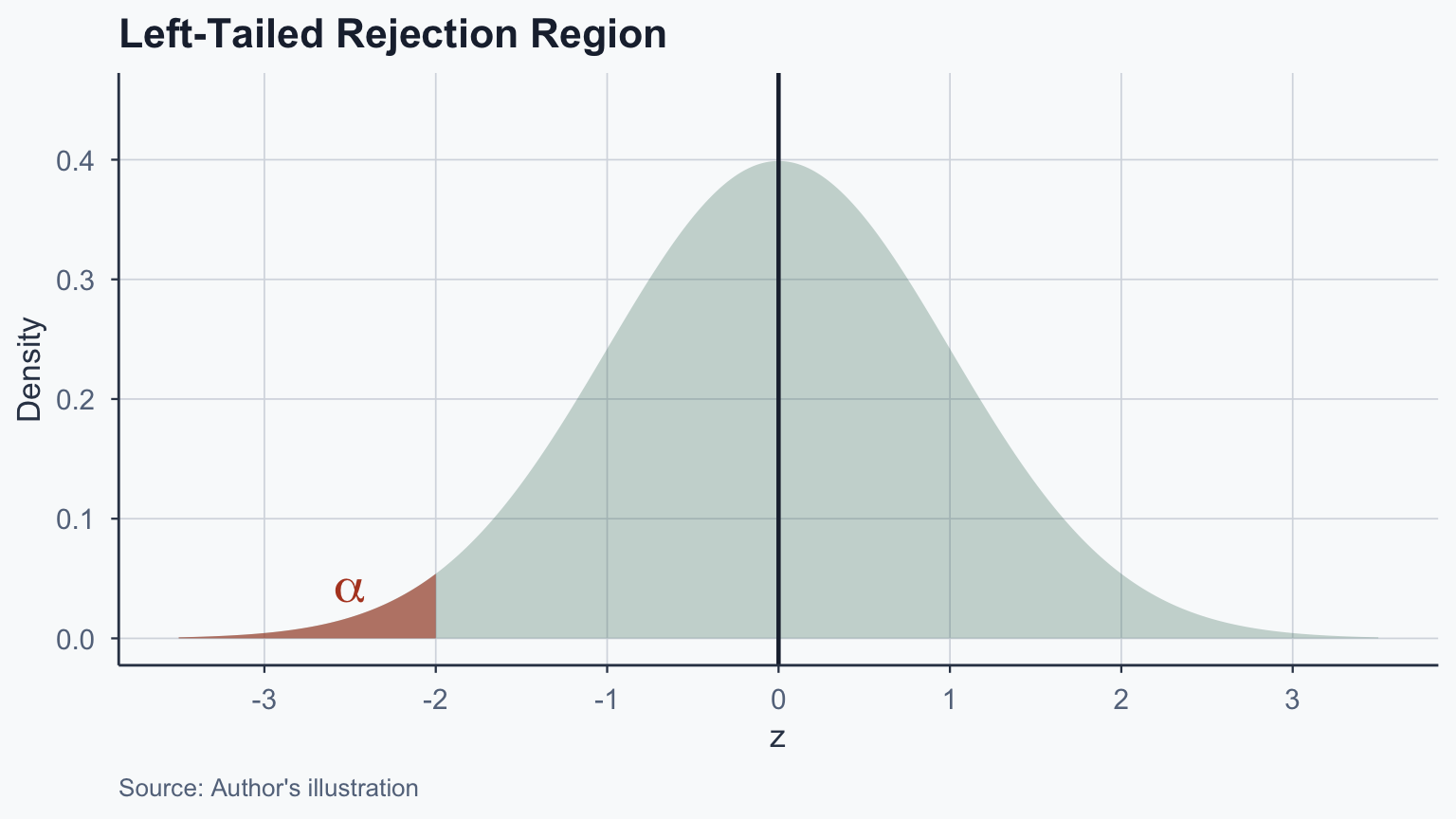
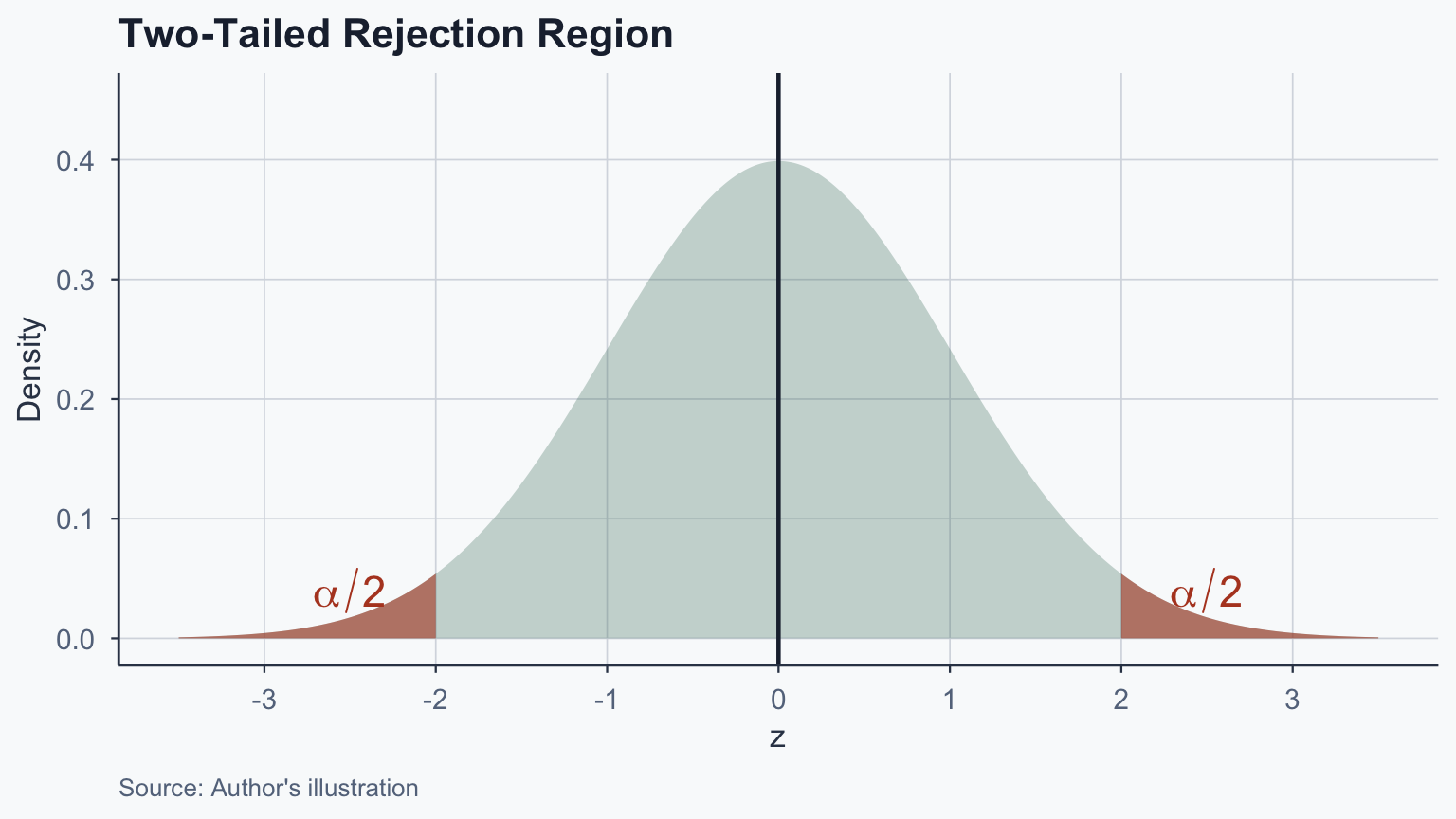
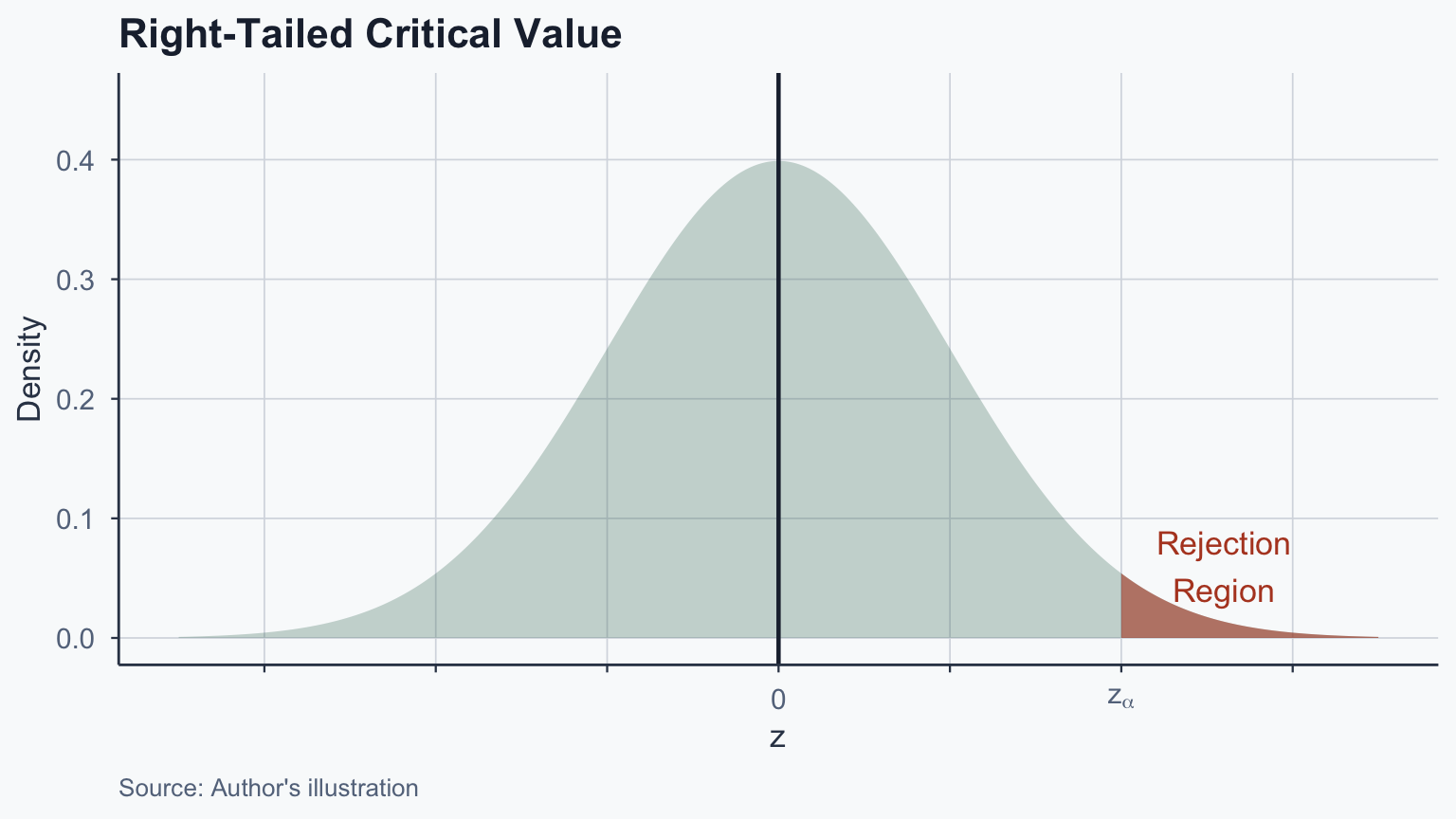
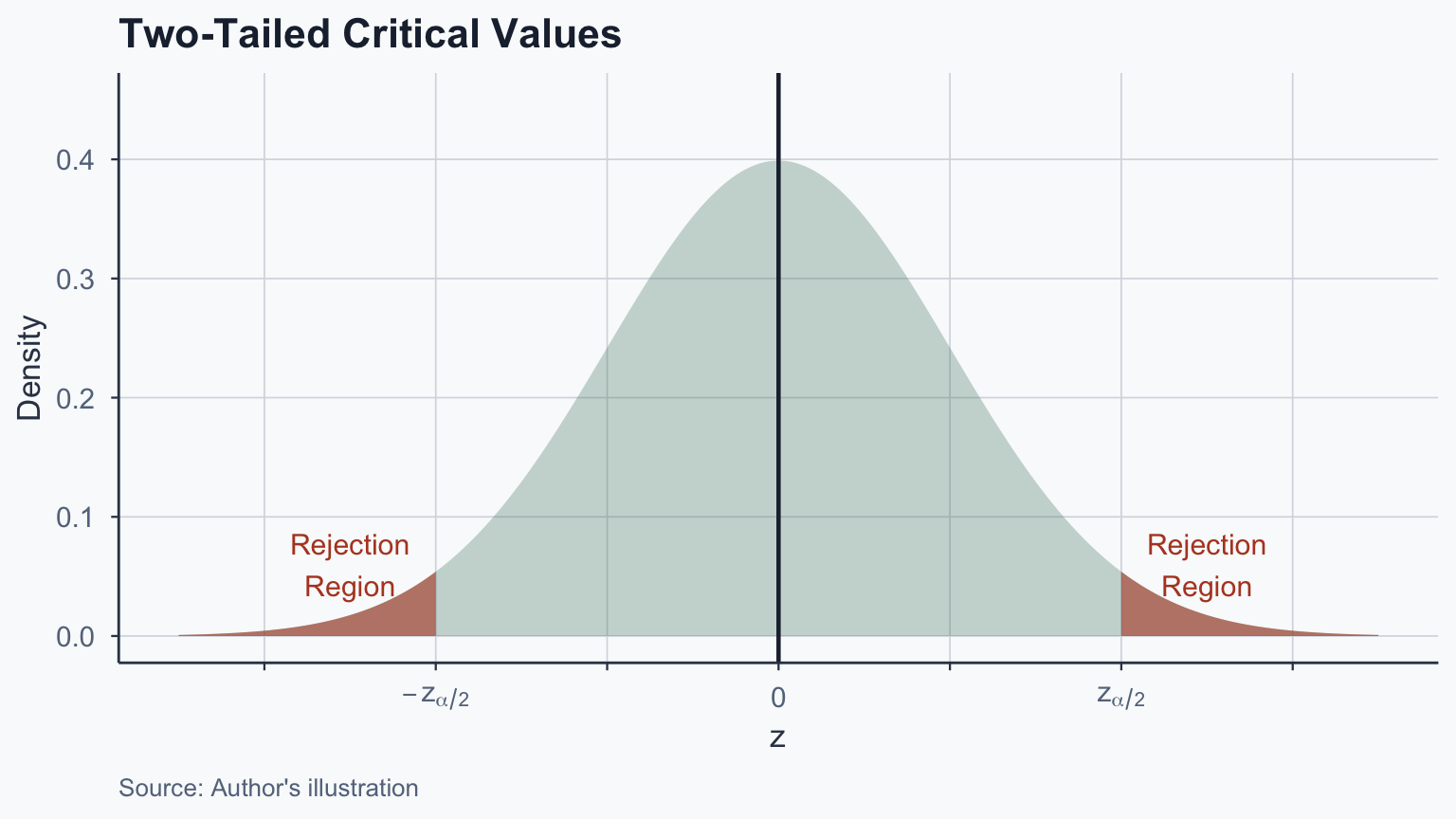
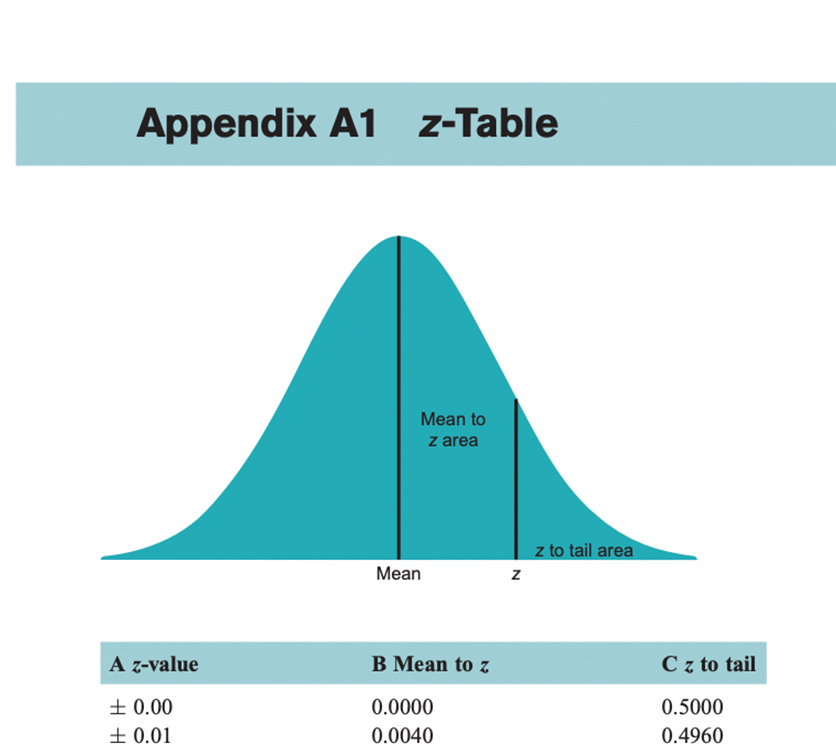
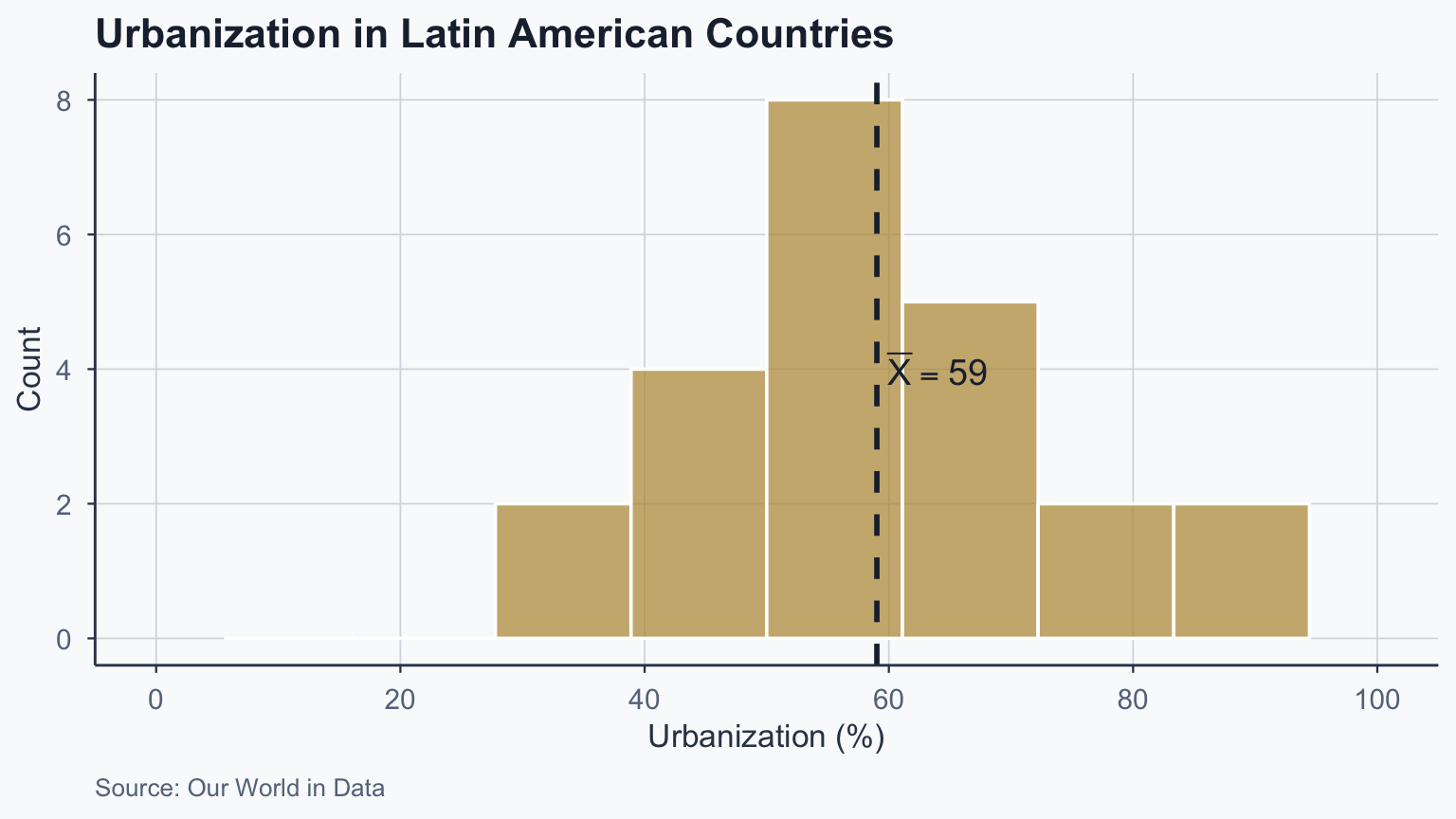
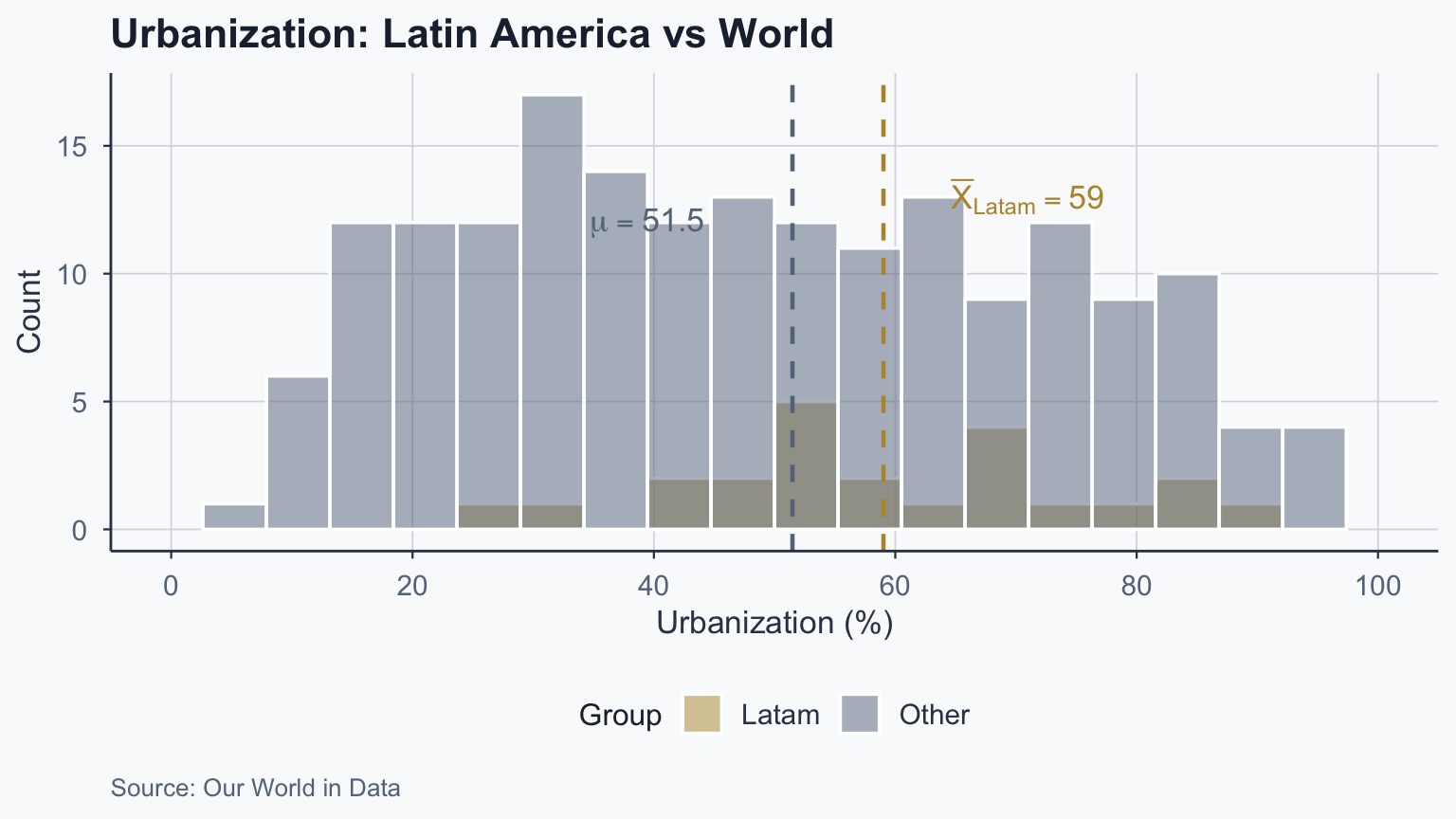
# One-sample z-test (manual computation)
z_obs_1 <- (latam_mean - pop_mean) / (pop_sd / sqrt(n_latam))
p_value_1 <- 2 * (1 - pnorm(abs(z_obs_1)))
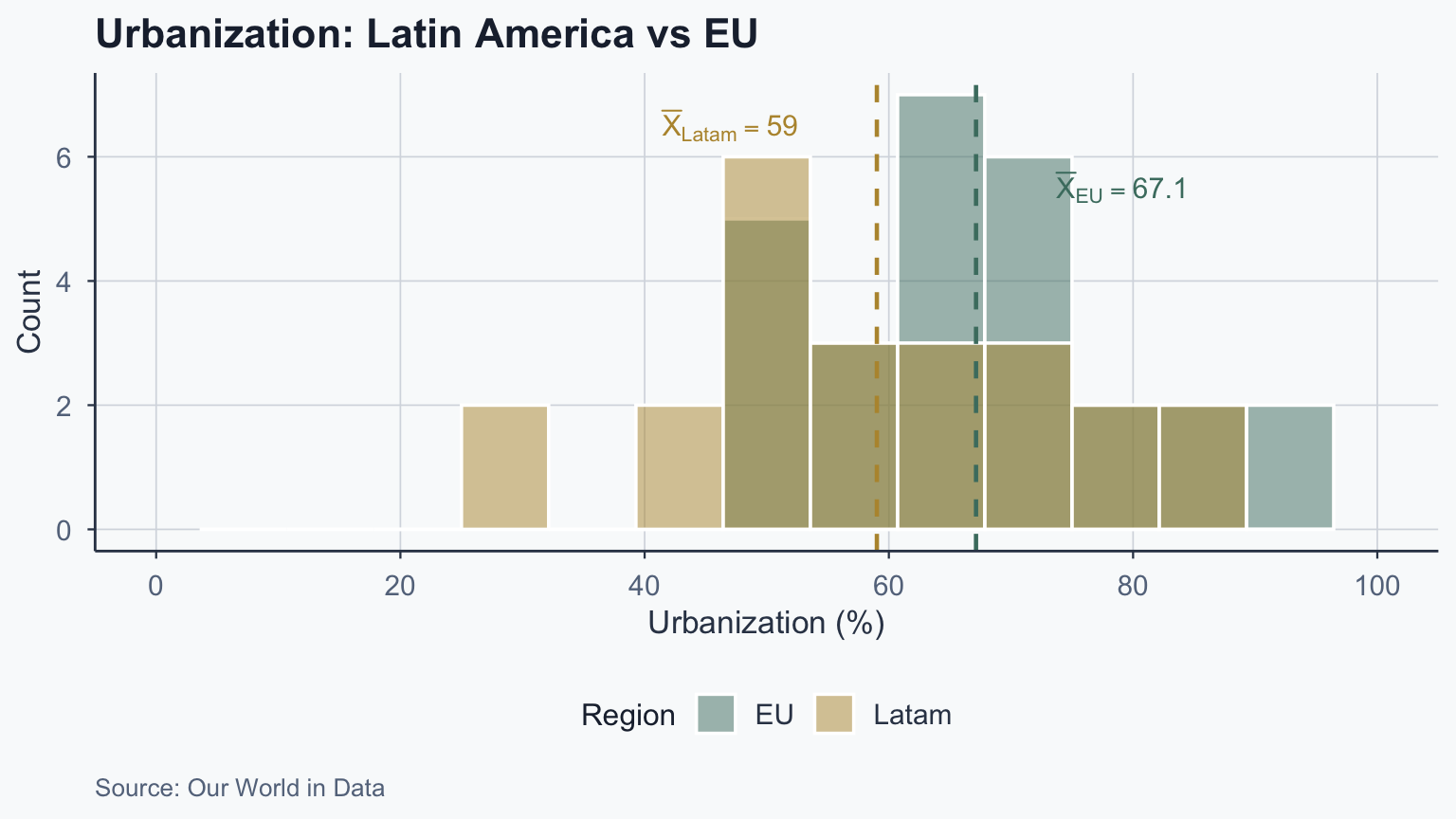
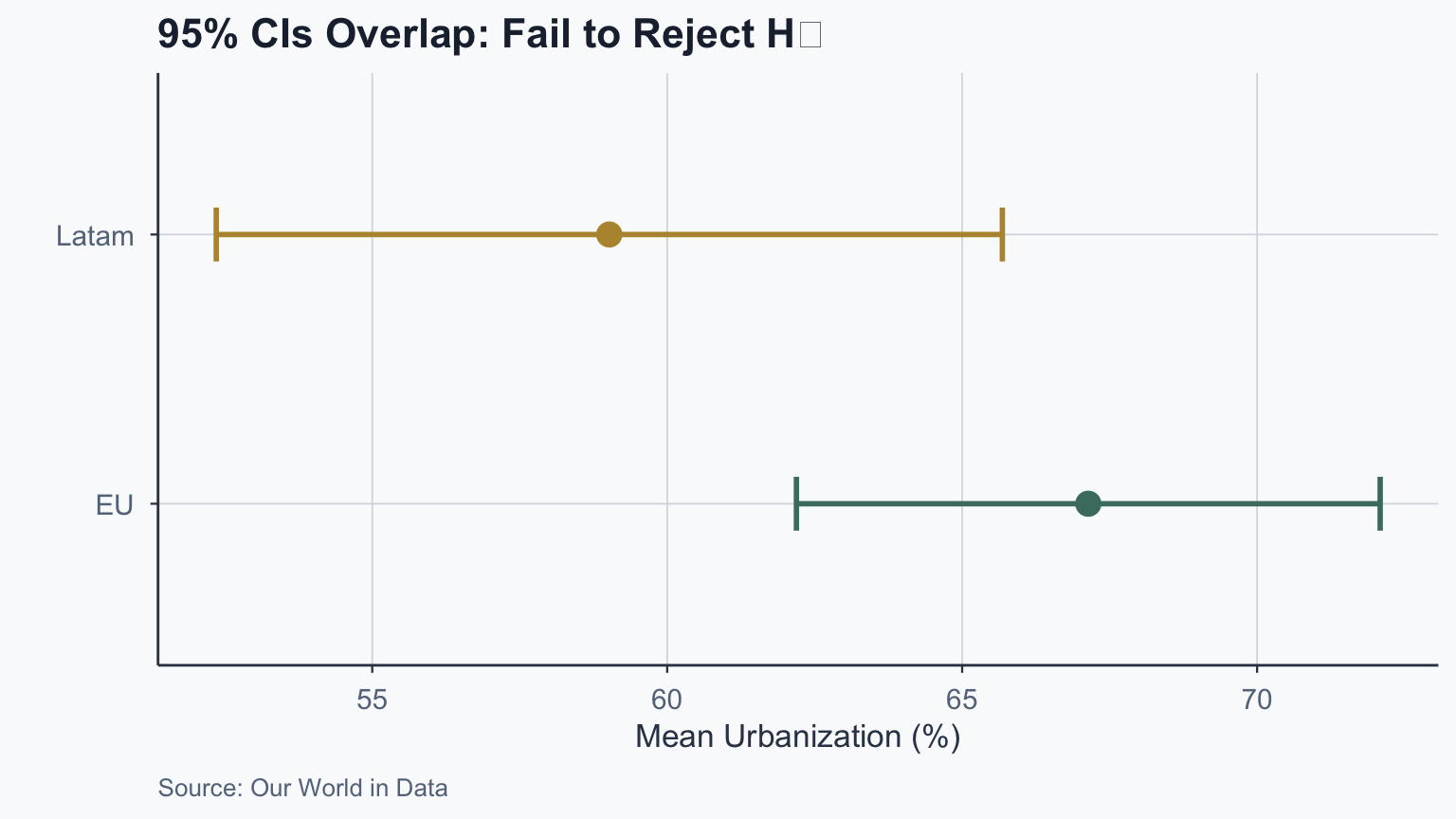
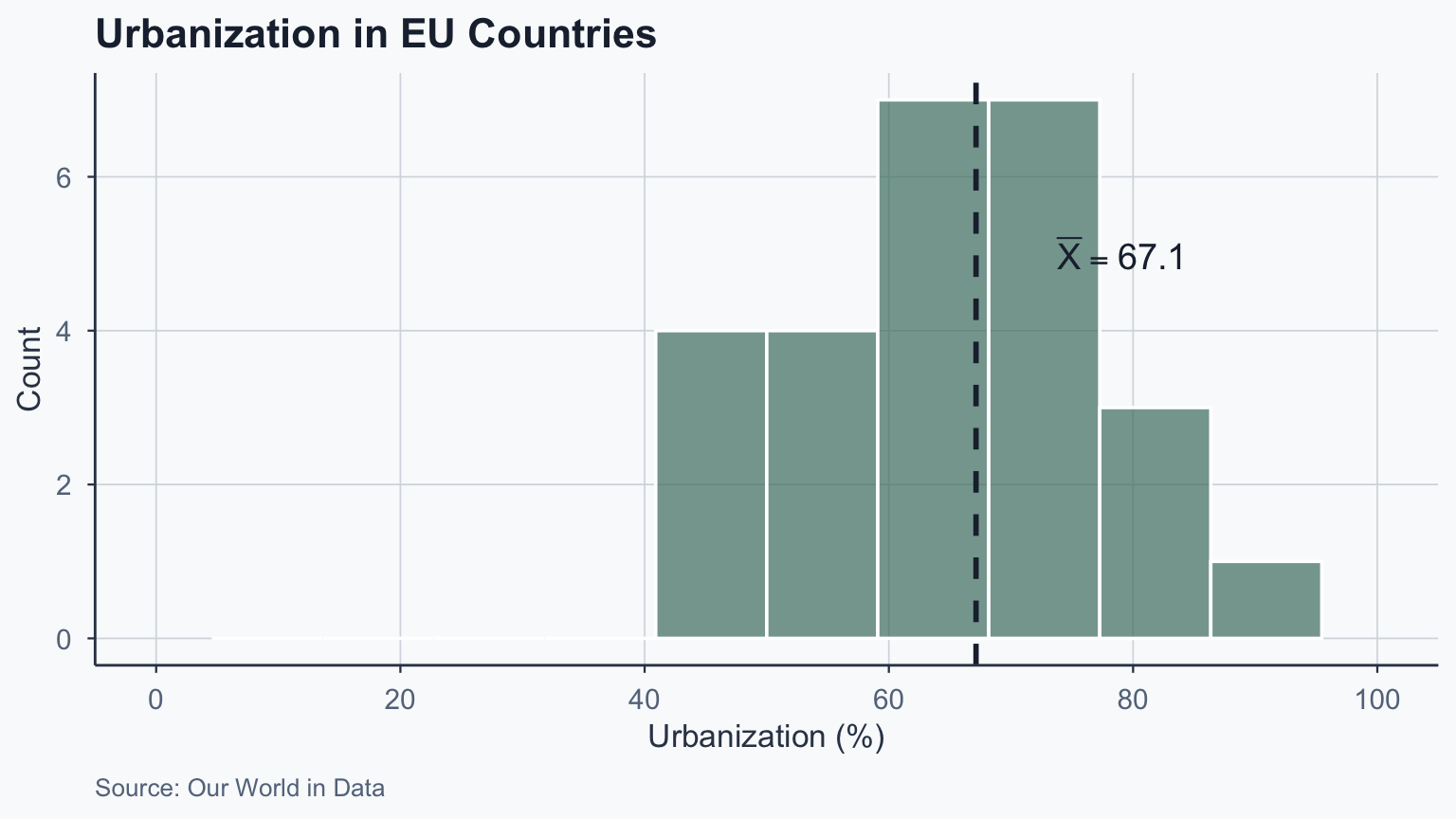
cat("z =", round(z_obs_1, 3), "\n")z = 1.498 p-value = 0.1341 Sample mean: 59.02 Population mean: 51.48