Statistical Analysis
Lecture 15: Revision for Final

John Cabot University
Regression on a Binary Explanatory Variable

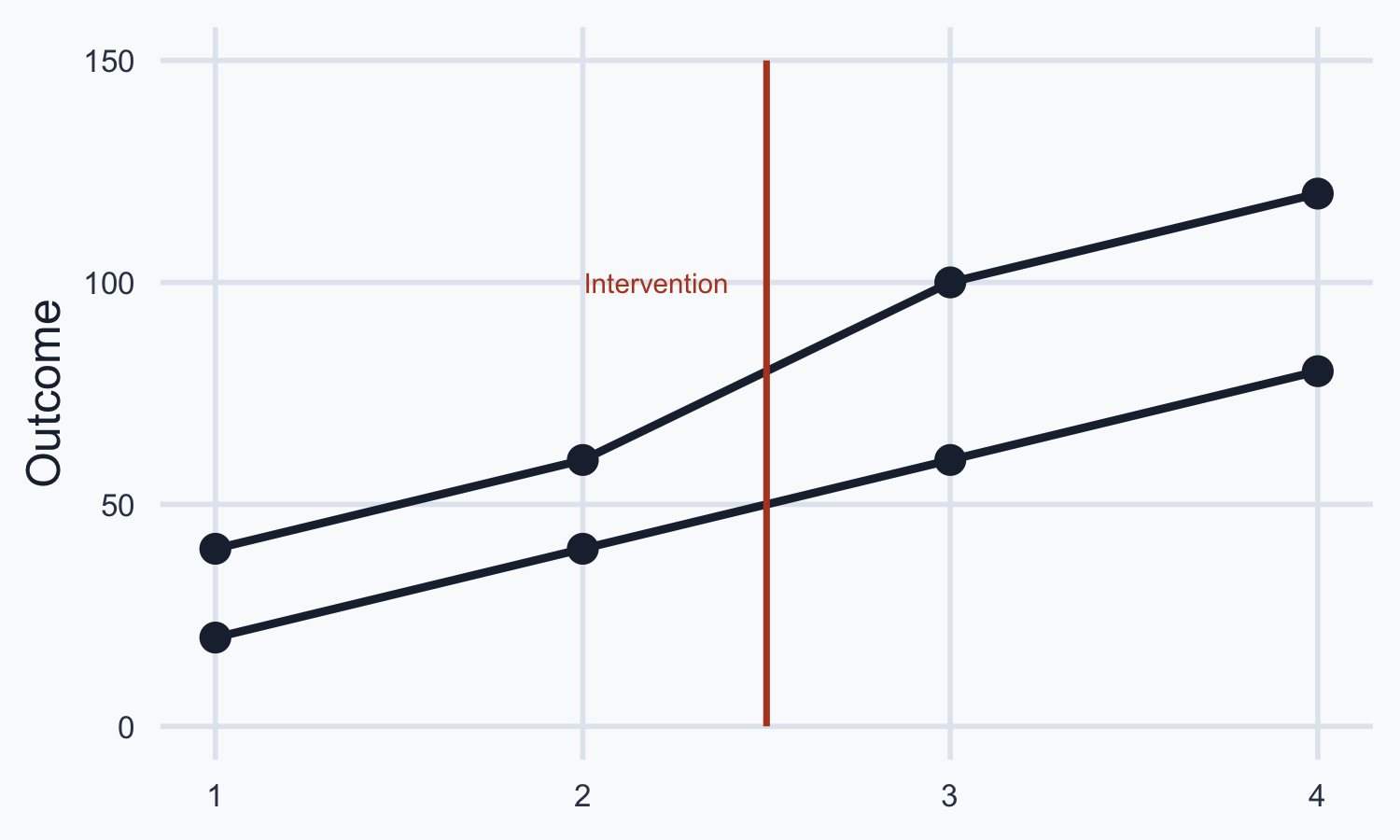
Example: Parallel Trends Hold
Pre-treatment trends are parallel — DiD is valid
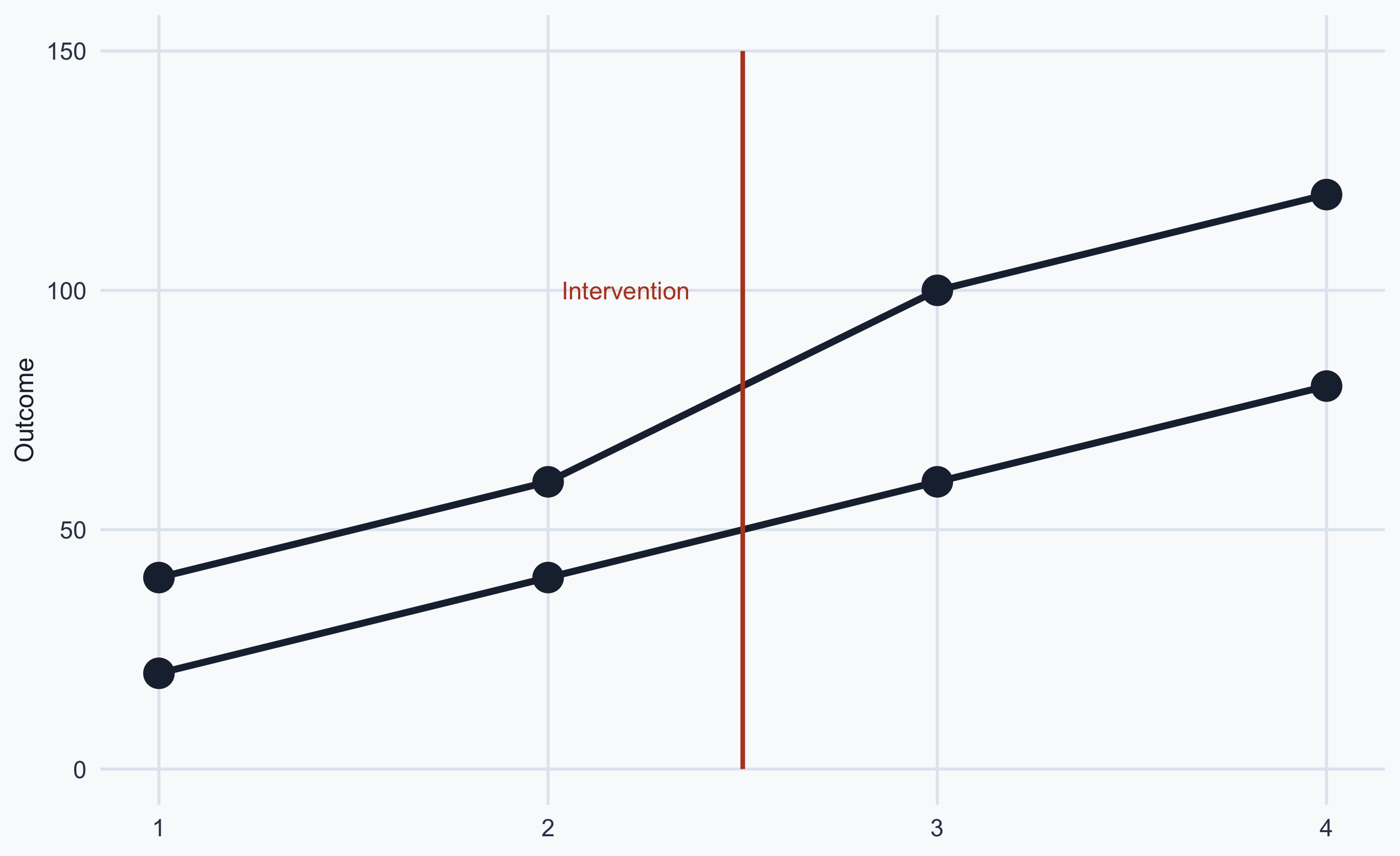
Example: Parallel Trends Violations
Pre-treatment trends diverge — DiD is not valid
Treatment Timing: Staggered Adoption
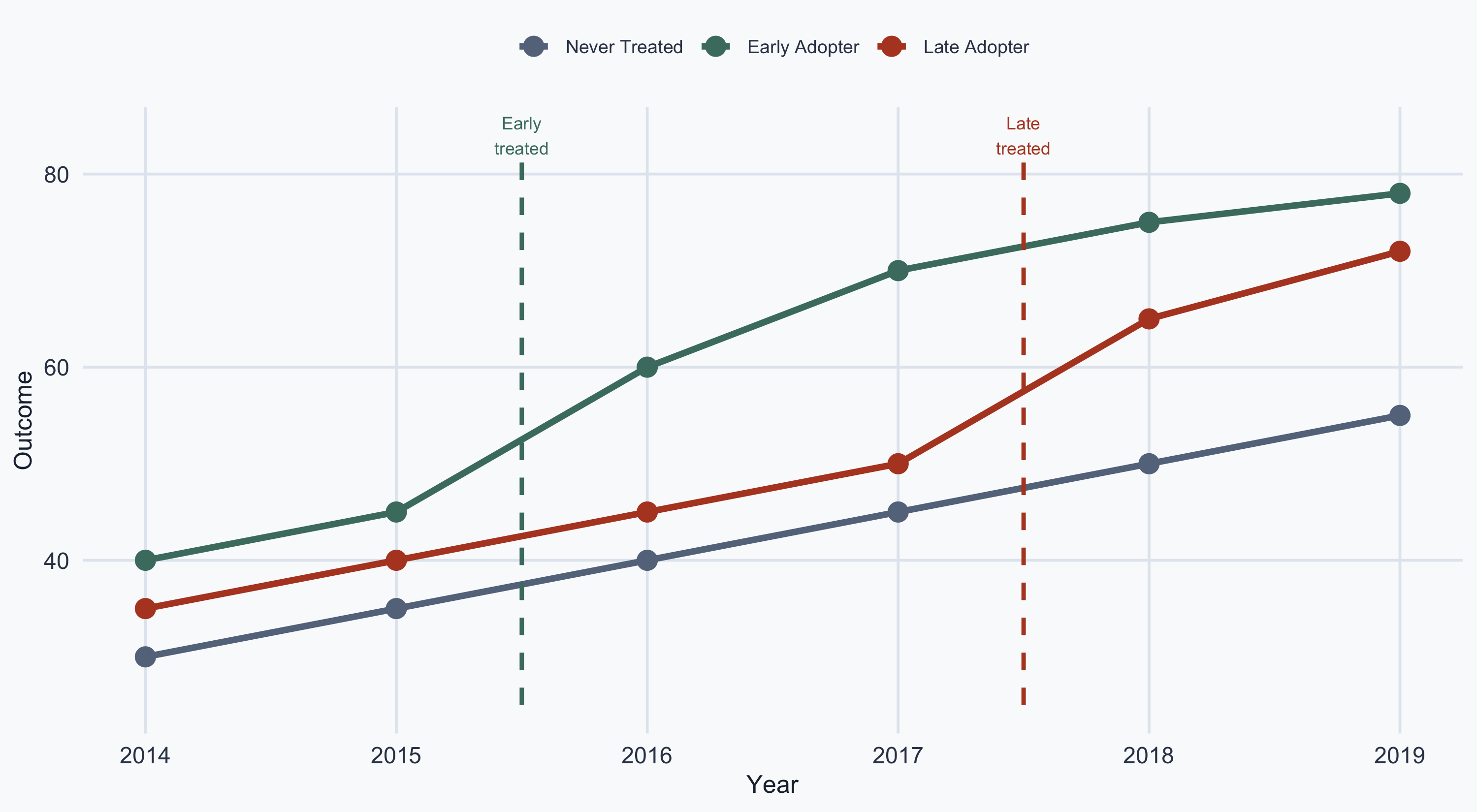
Already-treated “Early Adopters” used as controls for “Late Adopters” — biased estimates
Example Questions (2)
4. Interpret the coefficient for math score and for female

5. What can you say about the statistical significance of the two variables? Why?
Example Questions (3)
6. Look at the following regression predicting income (thousands of dollars per month). Male is a binary variable. Interpret it.

Example Questions (4)
8. Interpret the following coefficients
You are trying to explain health scores (0 to 10) using age (years) and weight (kilos) as independent variables.

Example Questions (6)
12. How can sample selection affect external validity?
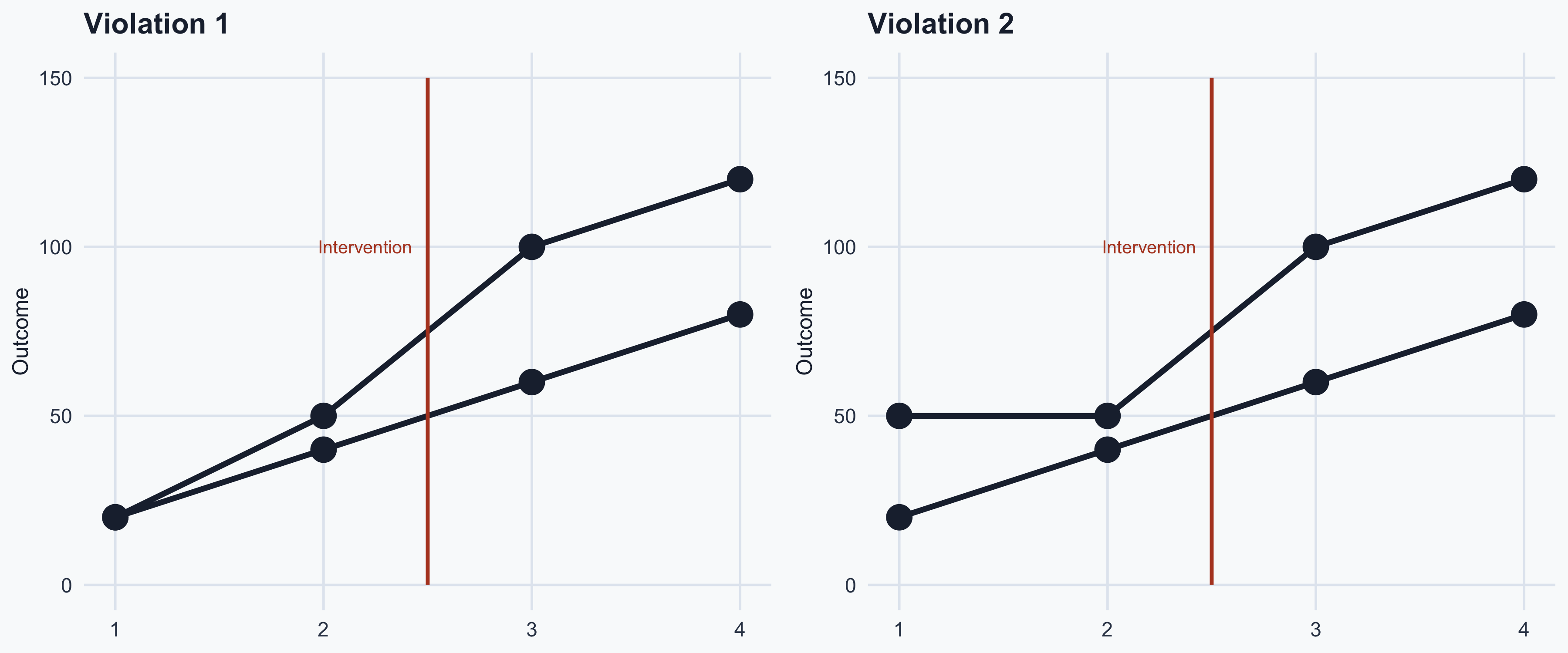
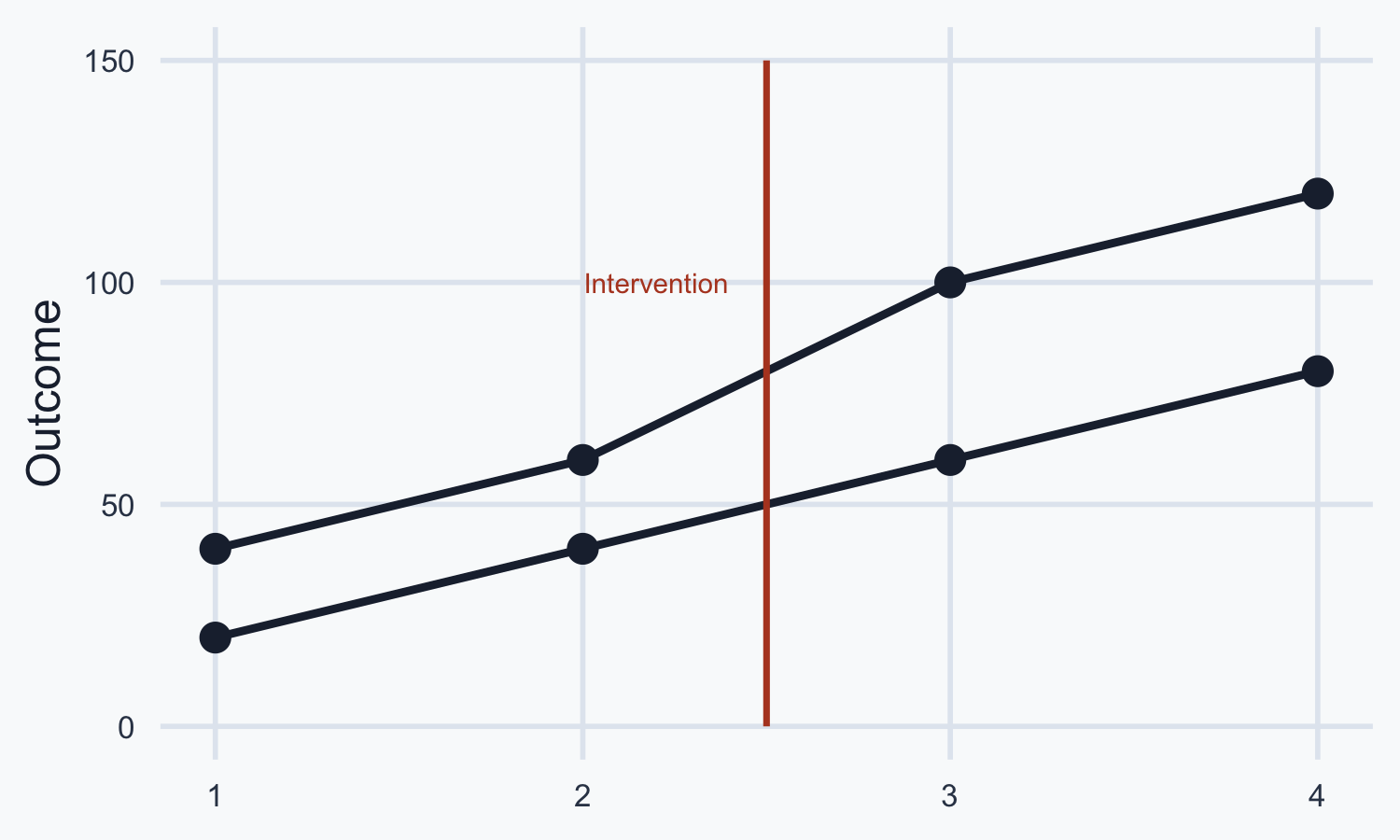
13. Examine the following graph. Do you see a violation of the parallel trends assumption? Answer Yes or No.
Answers (2)
4. Interpret the coefficients:
- For every point increase in math score, science score increases by 0.389, holding everything else constant
- Women have on average lower science scores by 2.010 compared to men, holding everything else constant
5. Only math is statistically significant at 5% because \(p < 0.05\). The female variable is significant at the 0.051 level.
Answers (3)
6.
Men make 249 dollars per month more than women, holding other factors constant.
7. Men make \(1{,}583 + 249 = 1{,}832\) dollars a month. Women make \(1{,}583\) dollars a month.
Answers (4)
8.
- Every year increase in age is associated with a decline in health of 0.019, holding everything else constant
- Every kilo is associated with more health, but this effect is not statistically significant
- Age and weight together have a statistically negative impact on health outcomes
Answers (6)
12. Sample selection is the process of selecting a sample that is not reflective of the actual population. The experimental sample may not be representative.
13. No.