Statistical Analysis
Lecture 11: Theories of Change
Bogdan G. Popescu 
John Cabot University
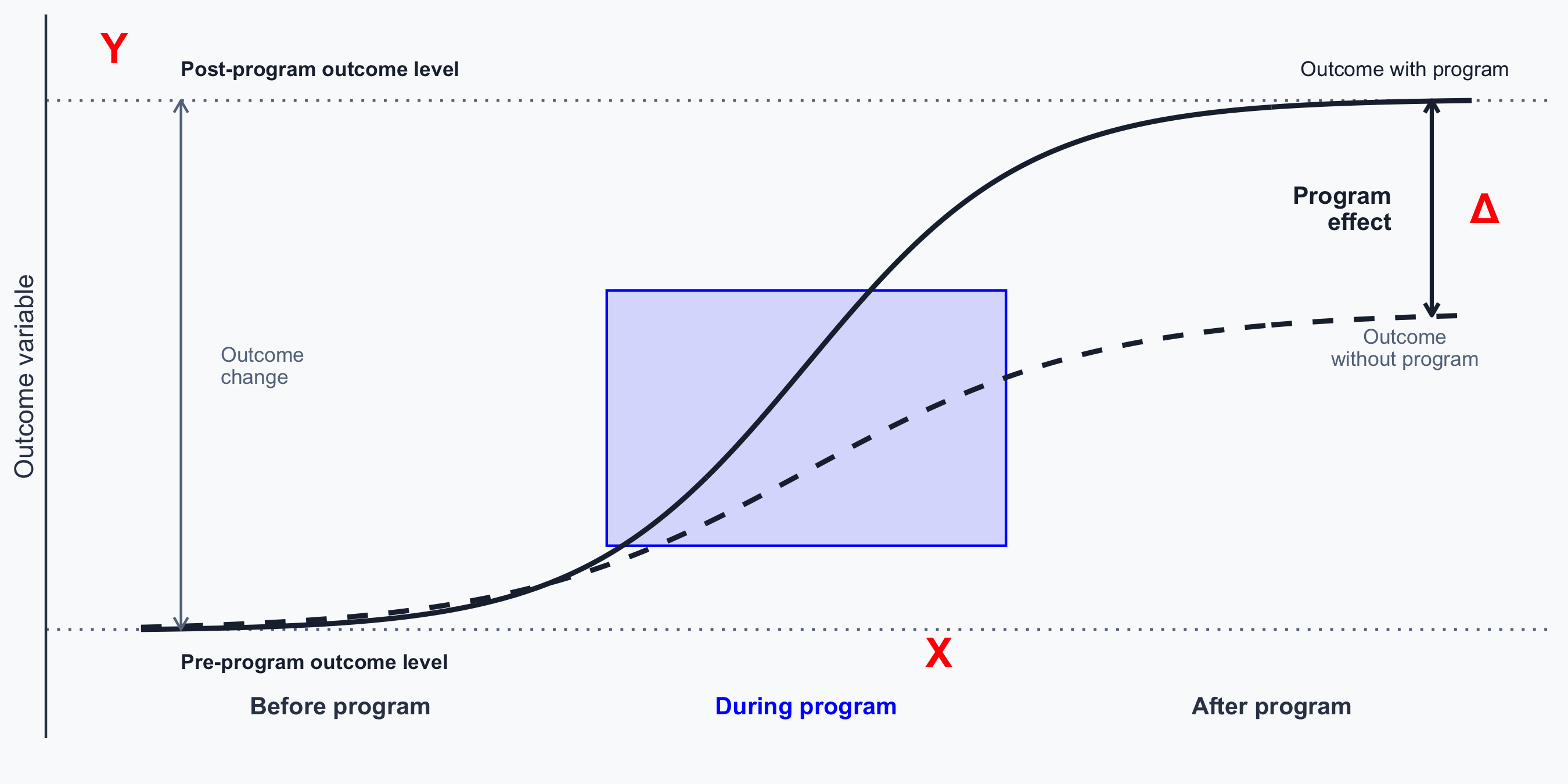
Outcomes and Programs
What Is a DAG?
Directed Acyclic Graphs (DAGs):
- Directed: arrows point from cause to effect
- Acyclic: no cycles; arrows go one direction only
- Graph: a visual representation of relationships
Steps 3–4: Connect Arrows
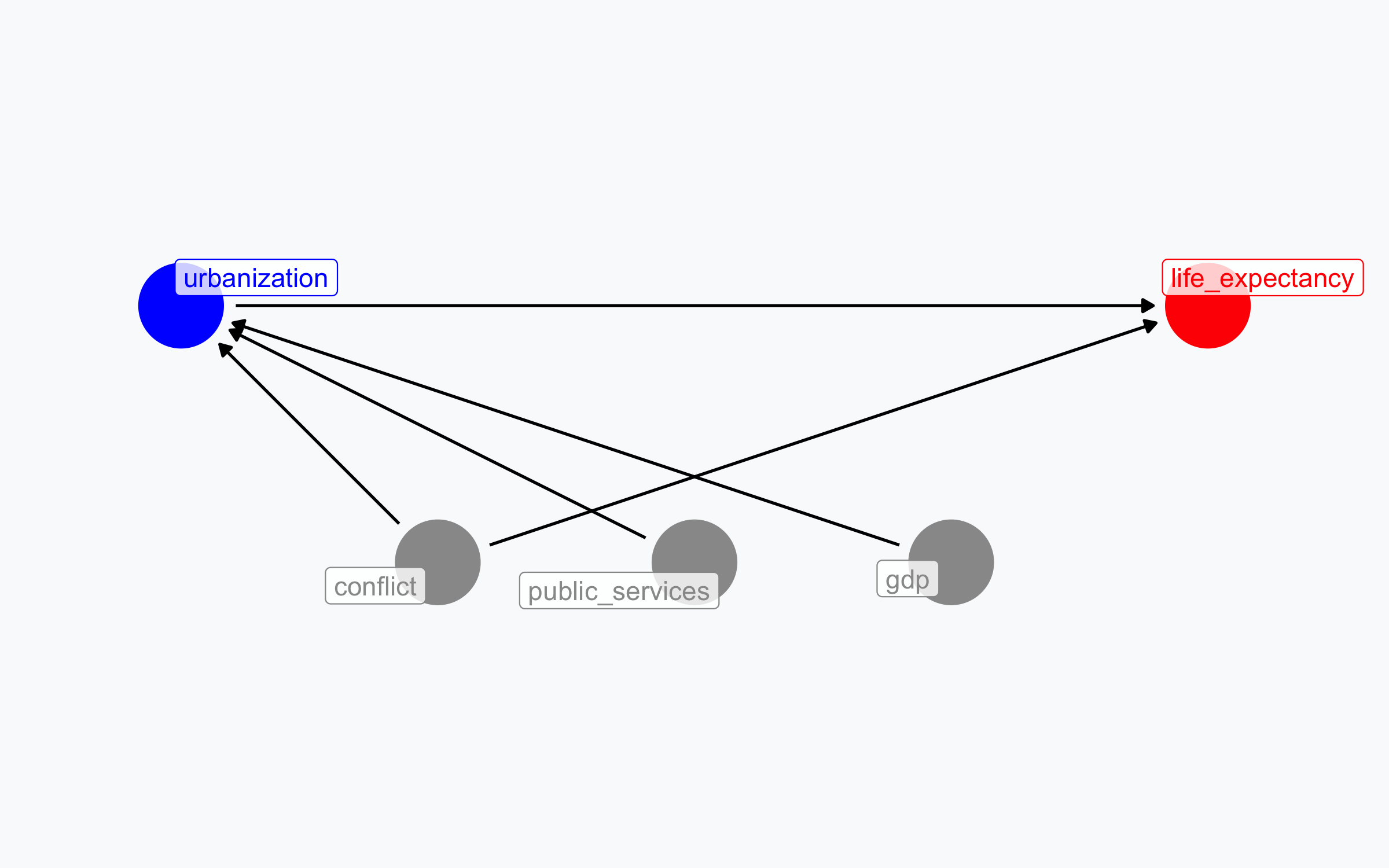
- GDP, conflict, public services \(\rightarrow\) urbanization
- Conflict also \(\rightarrow\) life expectancy directly
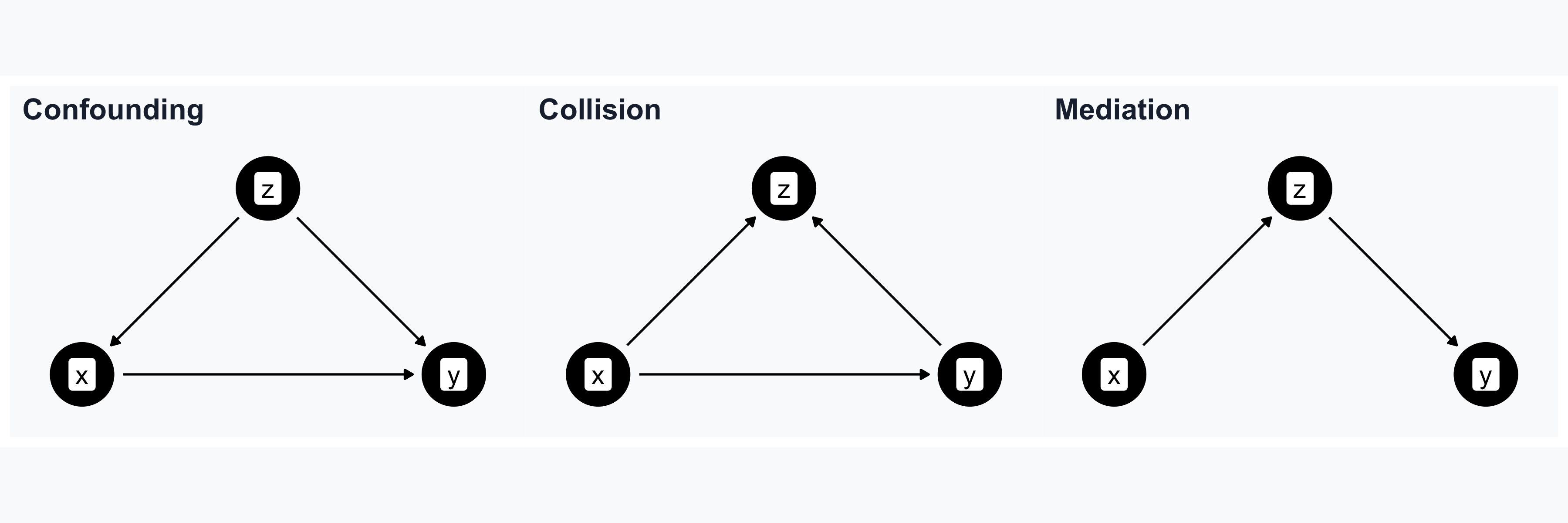
Confounding
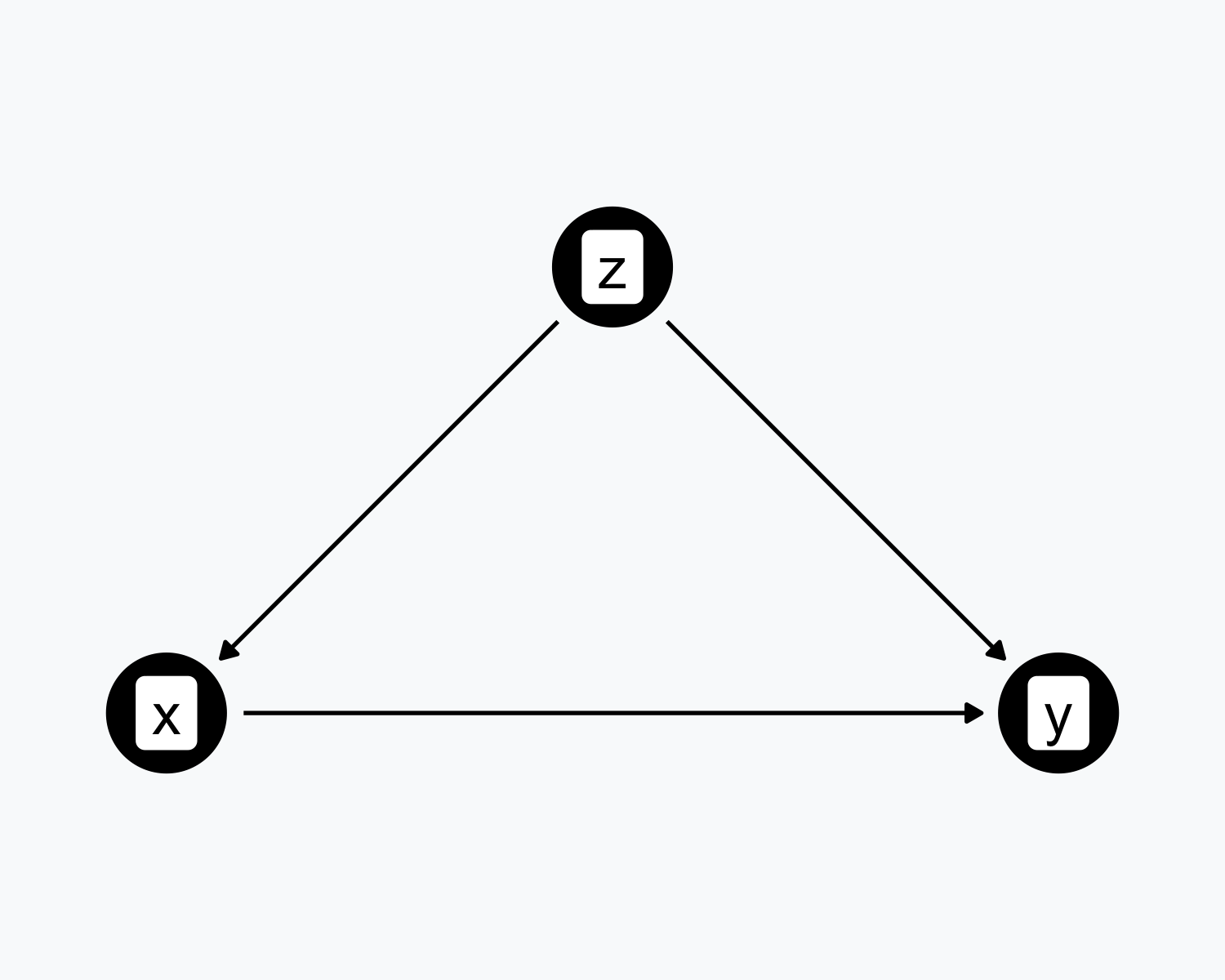
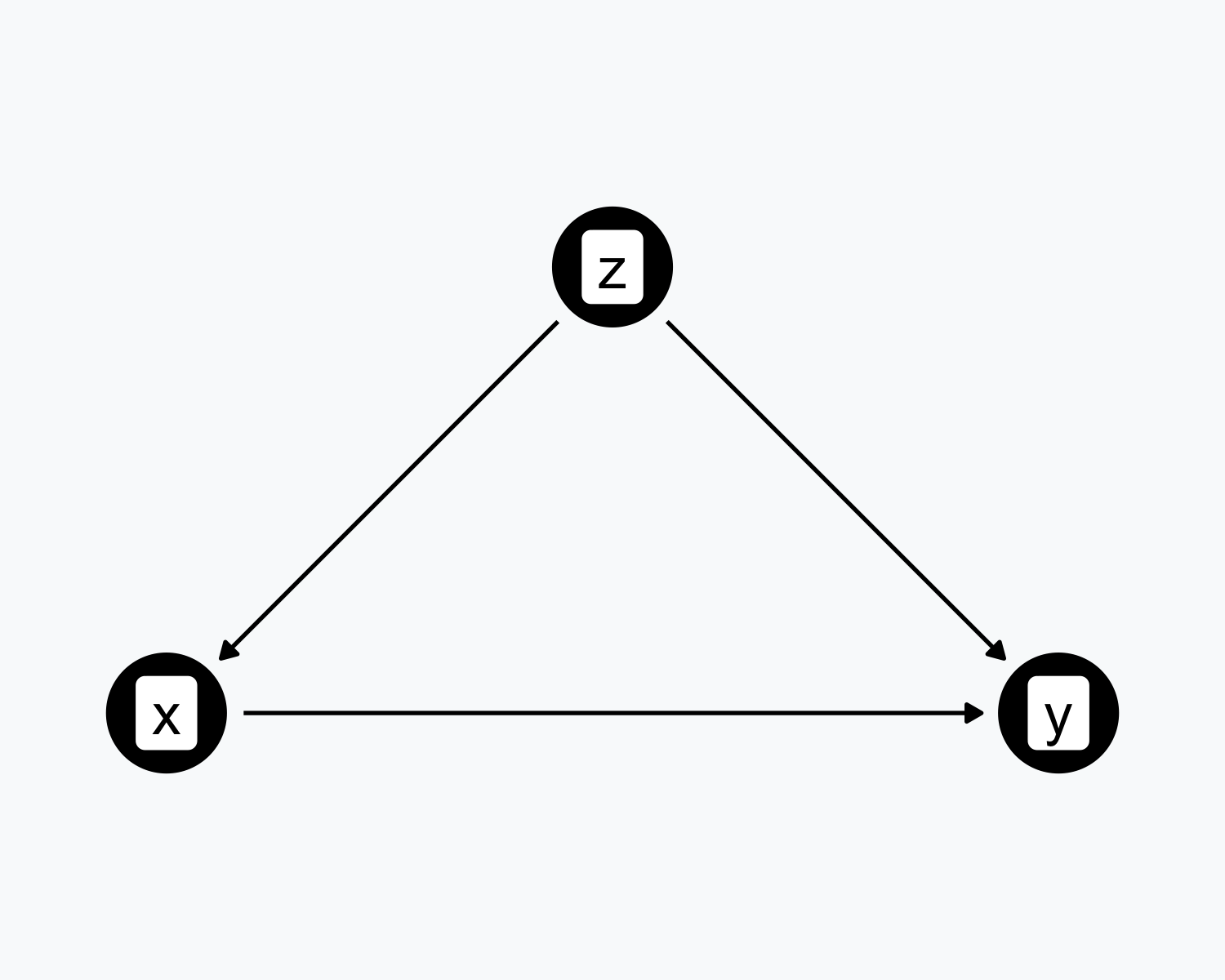
- \(Z\) causes both \(X\) and \(Y\)
- \(Z\) confounds the relationship between \(X\) and \(Y\)
- The \(X \rightarrow Y\) relationship is not identified
Confounding Example
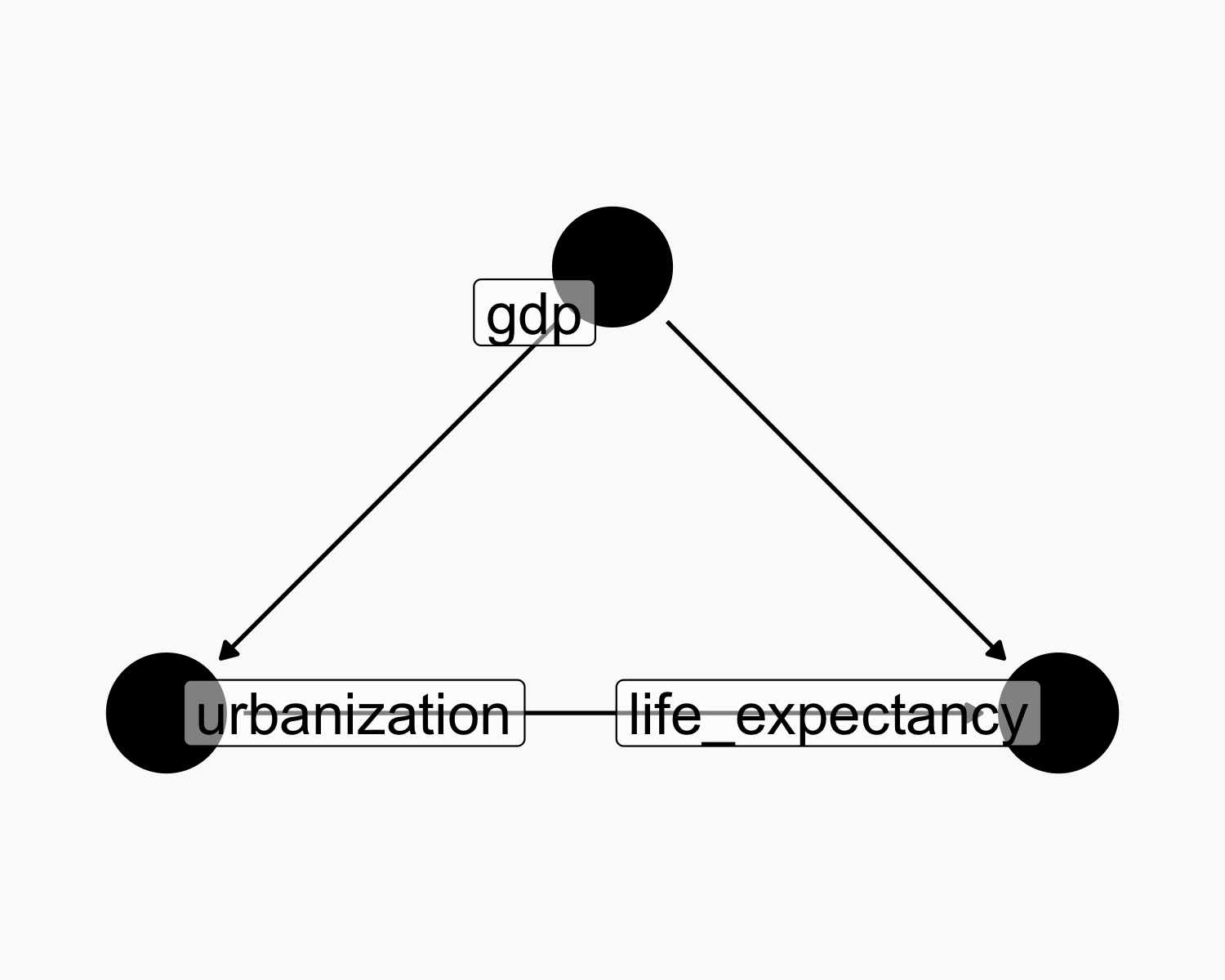
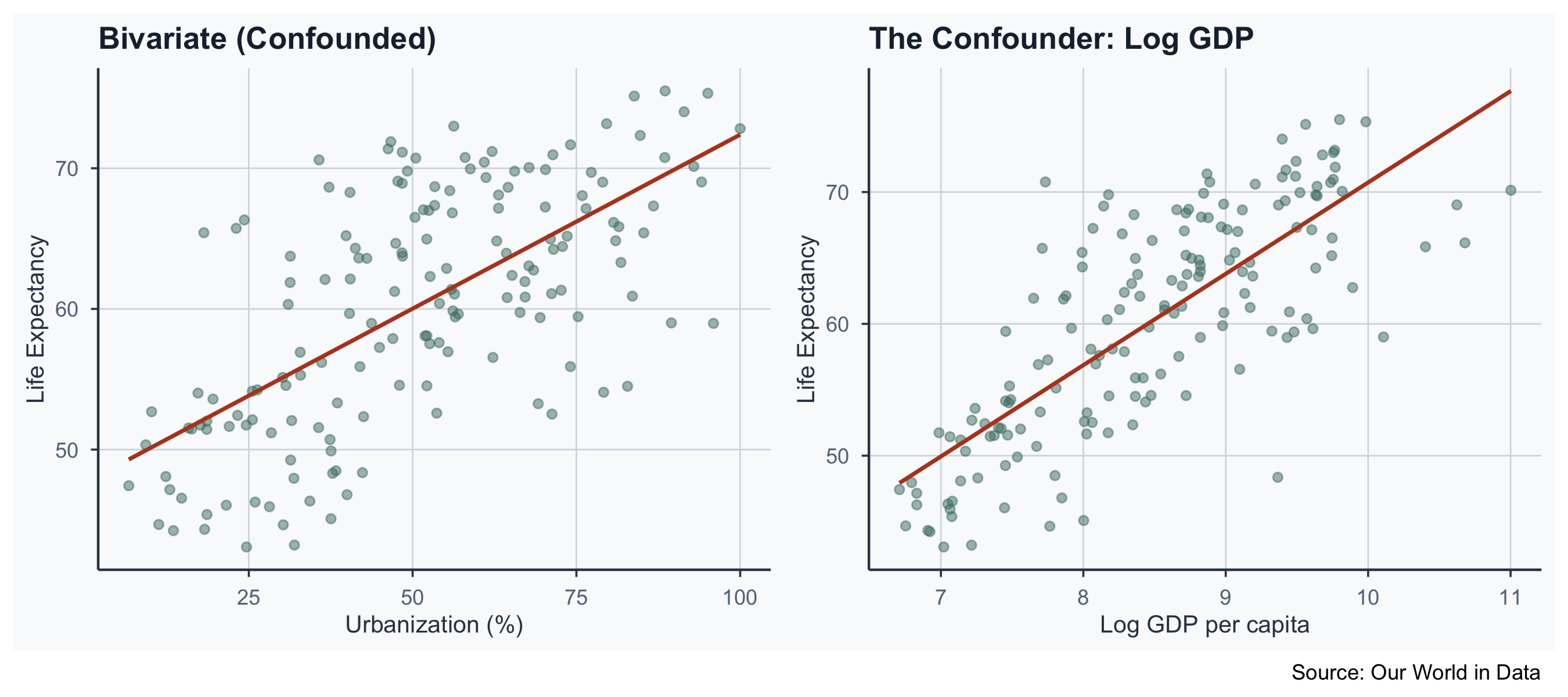
- GDP causes both urbanization and life expectancy
- GDP confounds the urbanization \(\rightarrow\) life expectancy link
- Without controlling for GDP, the effect is biased
Confounding: Visualized
Collision
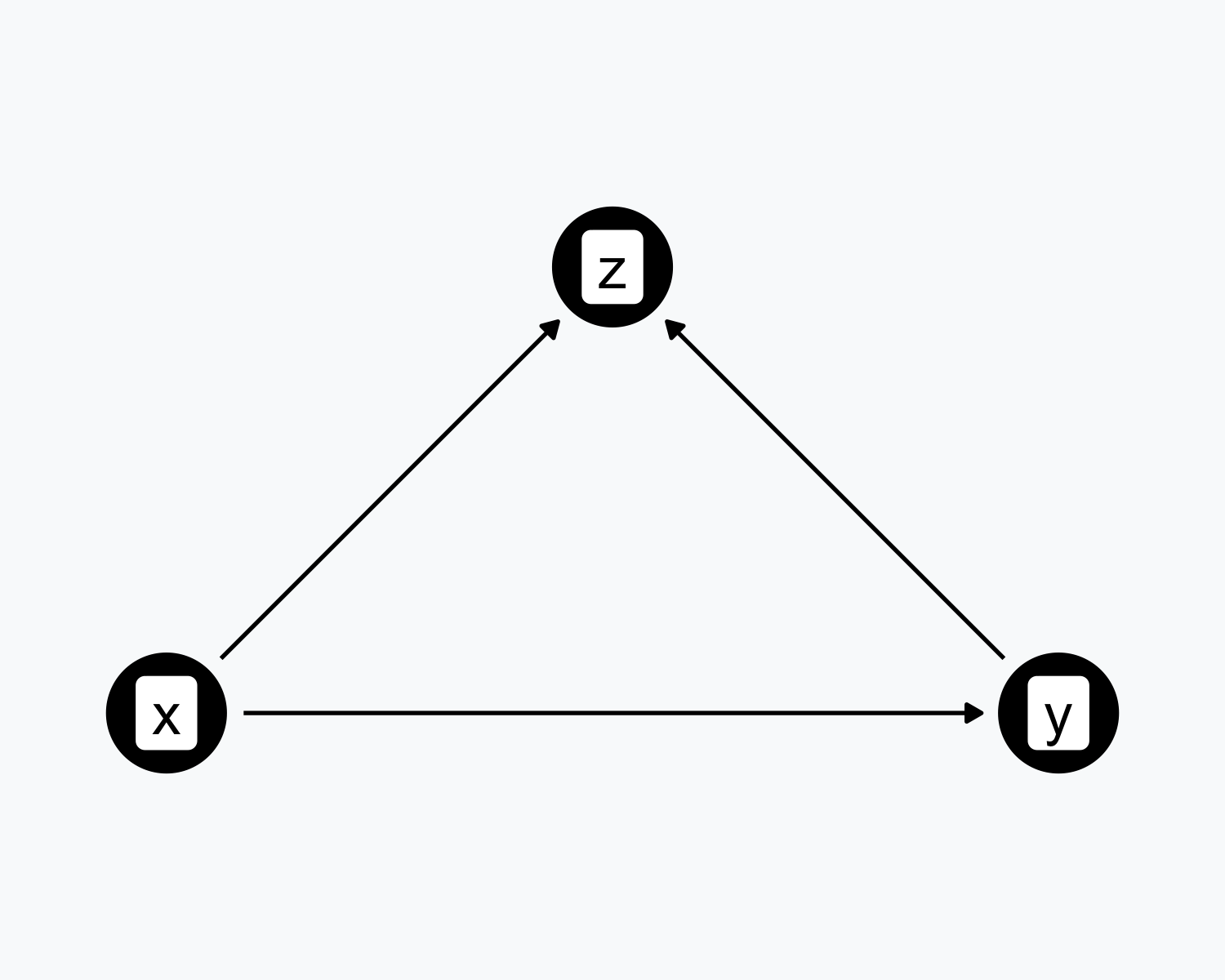
- \(X\) and \(Y\) both cause \(Z\) (the collider)
- Controlling for \(Z\) creates a spurious association
Collision Example
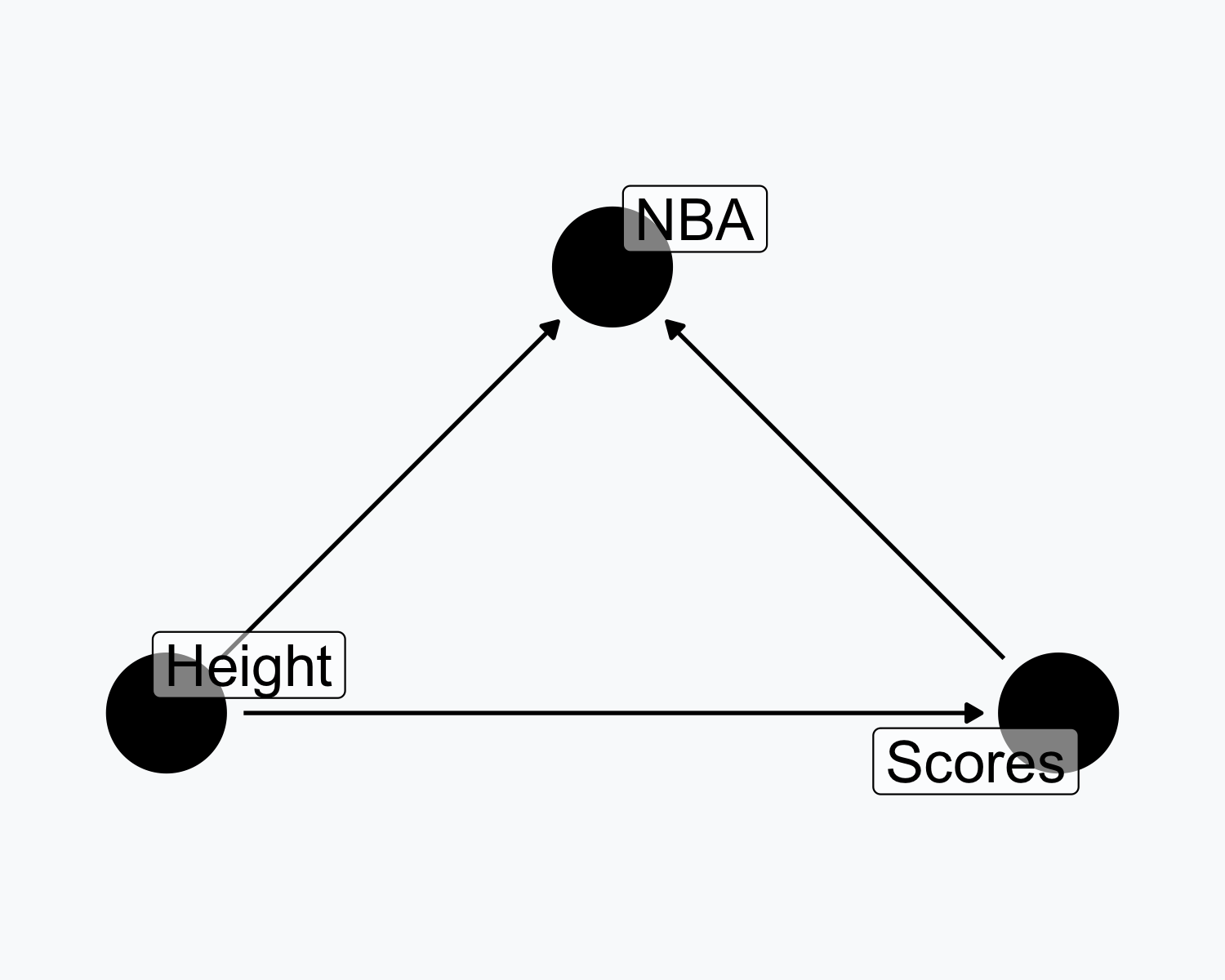
- Height and scoring both cause NBA recruitment
- Controlling for NBA status creates a false link
Mediation
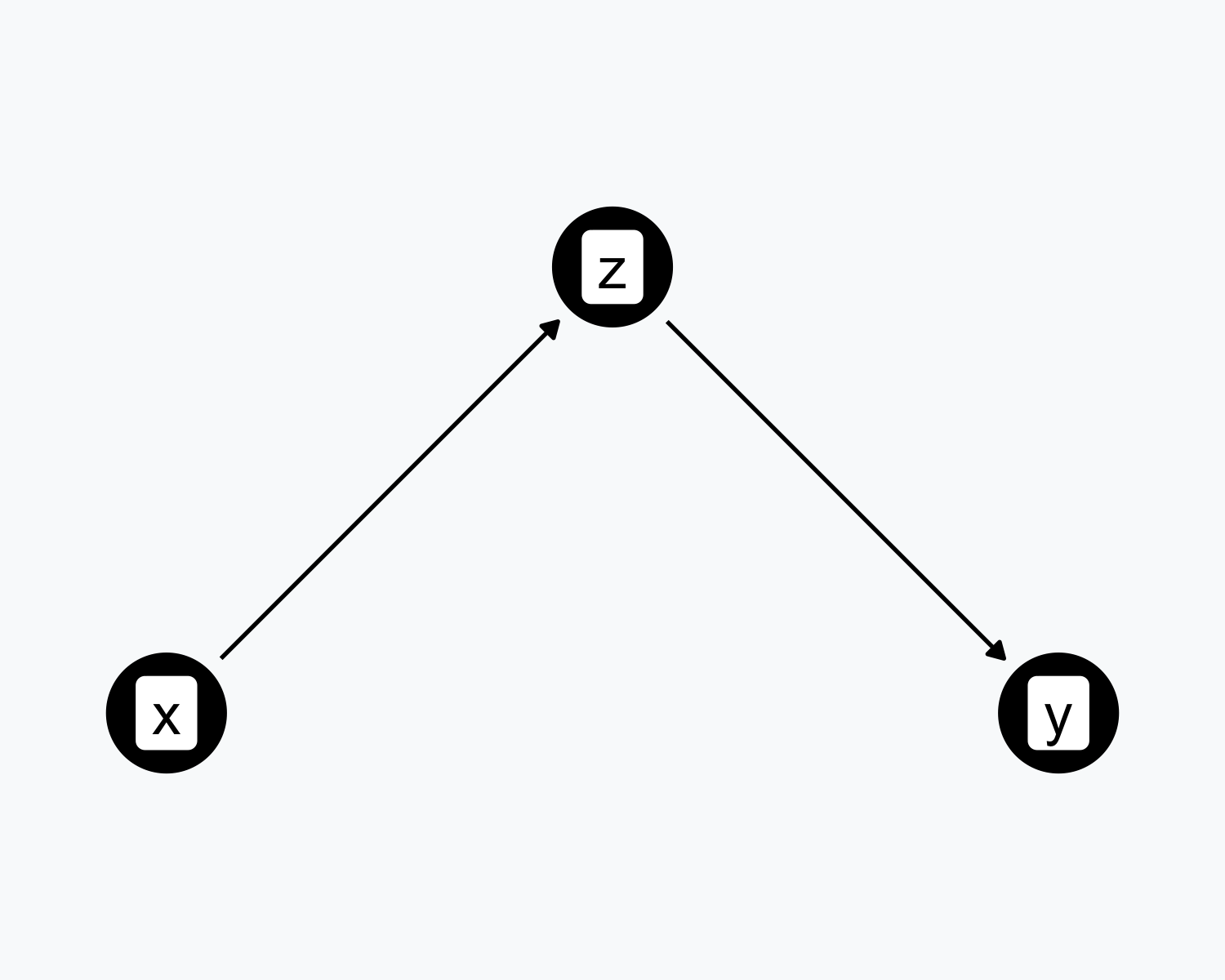
- \(X\) causes \(Z\), and \(Z\) causes \(Y\)
- \(Z\) is a mediator on the causal path
Mediation Example
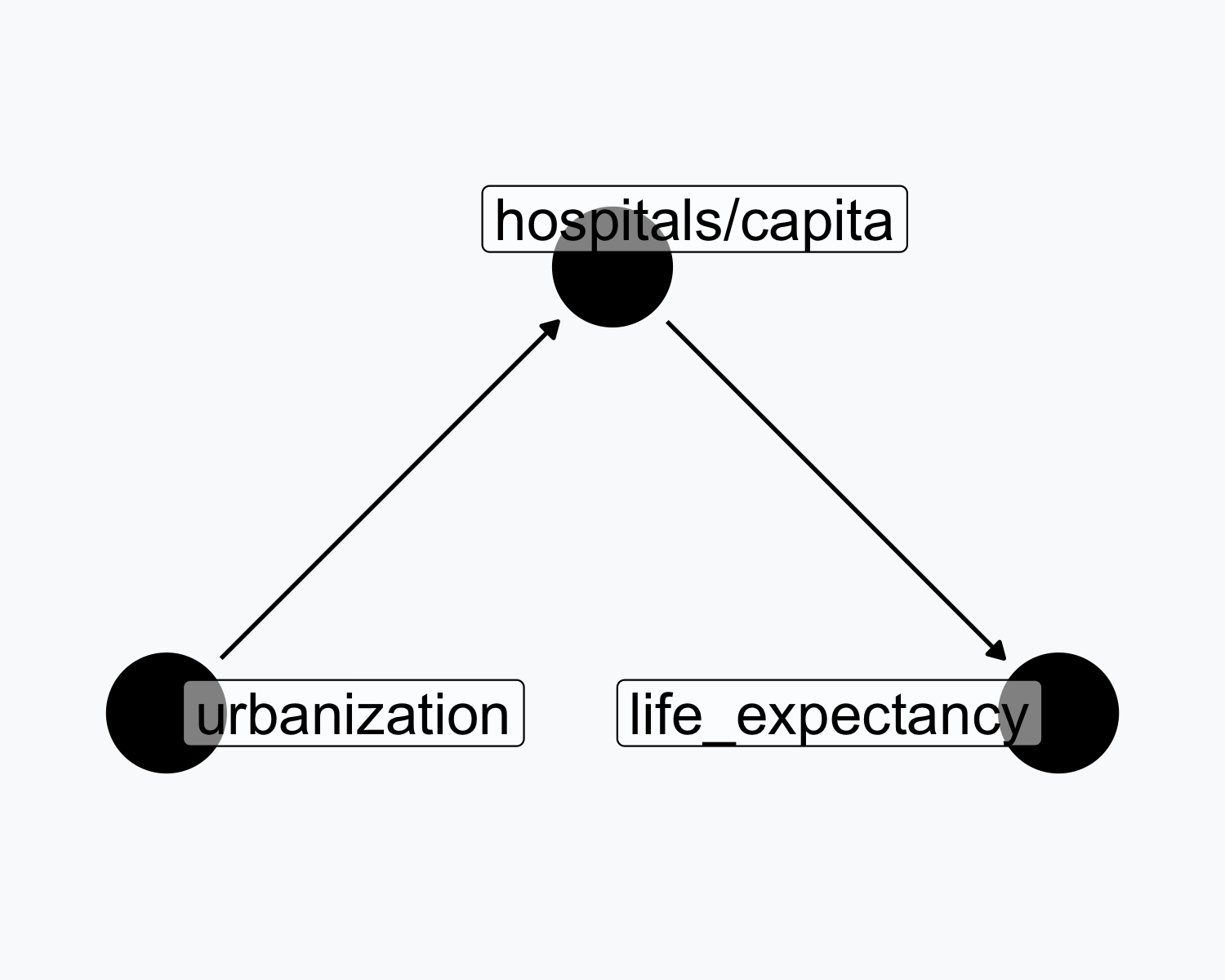
- Urbanization \(\rightarrow\) hospitals/capita \(\rightarrow\) life expectancy
- Hospitals mediate the urbanization effect
Full vs. Partial Mediation
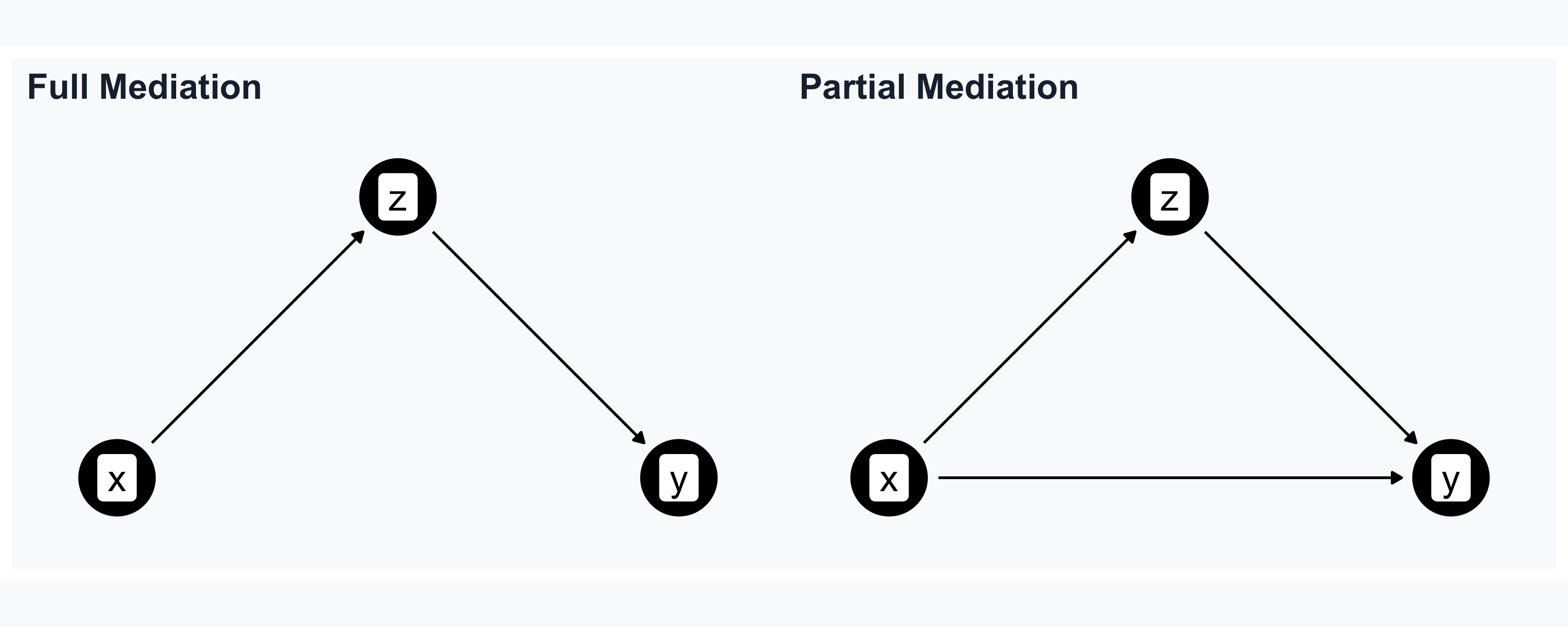
- Full: all of \(X\)’s effect passes through \(Z\)
- Partial: \(X\) affects \(Y\) directly and through \(Z\)
Summary of Variable Relationships
Causality in RCTs
In RCTs, we control who gets treated — confounders vanish
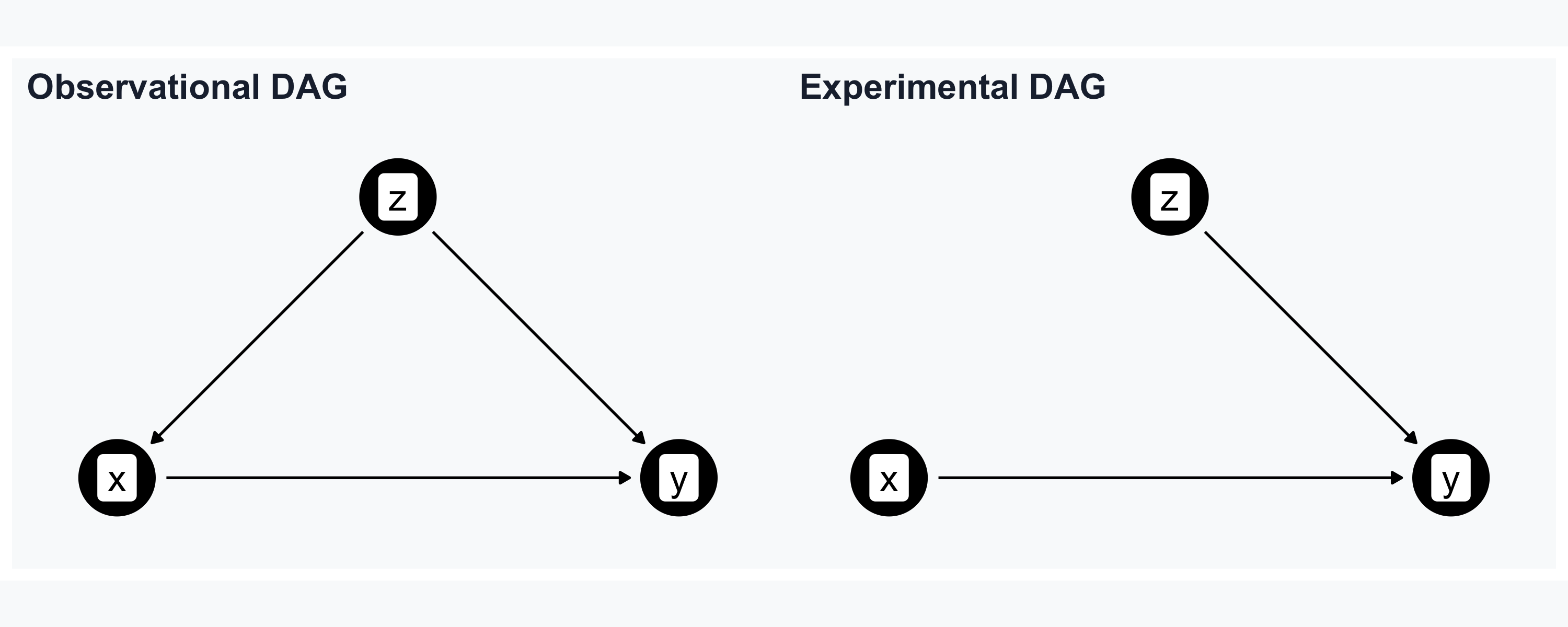
- Randomization breaks the arrow from \(Z\) to \(X\)
The Counterfactual Problem